When evaluating databases, we often think about each database as its own identity. For example, if we want to do transactional operations, SQL is a good database to consider. In terms of model flexibility, NoSQL may trump SQL if the model changes often. Then, we have the modern distributed SQL database, such as Google Spanner, that can provide global transactions and strongly consistent reads.
However, it is paramount to understand the underlying storage engine within these databases to explain how databases deliver these promises. For instance, why are relational databases very useful for performing transactional operations? What is the storage engine underlying SQL that makes transaction operations a good fit?
There are big differences between storage engine optimized for transactional workload vs. optimized for analytics. However, in this article, we will talk about two storage engine families that powers the widely used databases in most applications - SQL and NoSQL.
Why do You Have to Care?
You might be thinking, “Why do I even care about what the internal database storage engine operates? I probably will not implement my own storage engine from scratch in my software engineer career.”
However, you might need to know the fundamentals of how an internal database storage engine works to make appropriate design choices for your application.
Knowing these two types of storage engine makes you understand what all the buzz and the marketing in the paper is all about.
Moreover, knowing these two types of storage engines helps you decide why you want to use MongoDB instead of Cassandra.
These two types of storage engines can help you tune a storage engine to perform well on your kind of workload.
Therefore, if you are interested - without further ado, this article will explain two families of storage engines: Log-structured storage engines and page-oriented storage engines (B-Tree), and examine the Pros and Cons of each.
Log-Structured Segment Storage Engine (LSM Tree Engine)
A log-structured storage engine is the easiest and simplest form of a database. It breaks down the database into segments, typically several megabytes or more in size, and write is always in sequence.
The log-structured storage engine’s idea is to treat the database as an append-only log file and always append our data to its end. Once it writes to the disk, it is immutable.
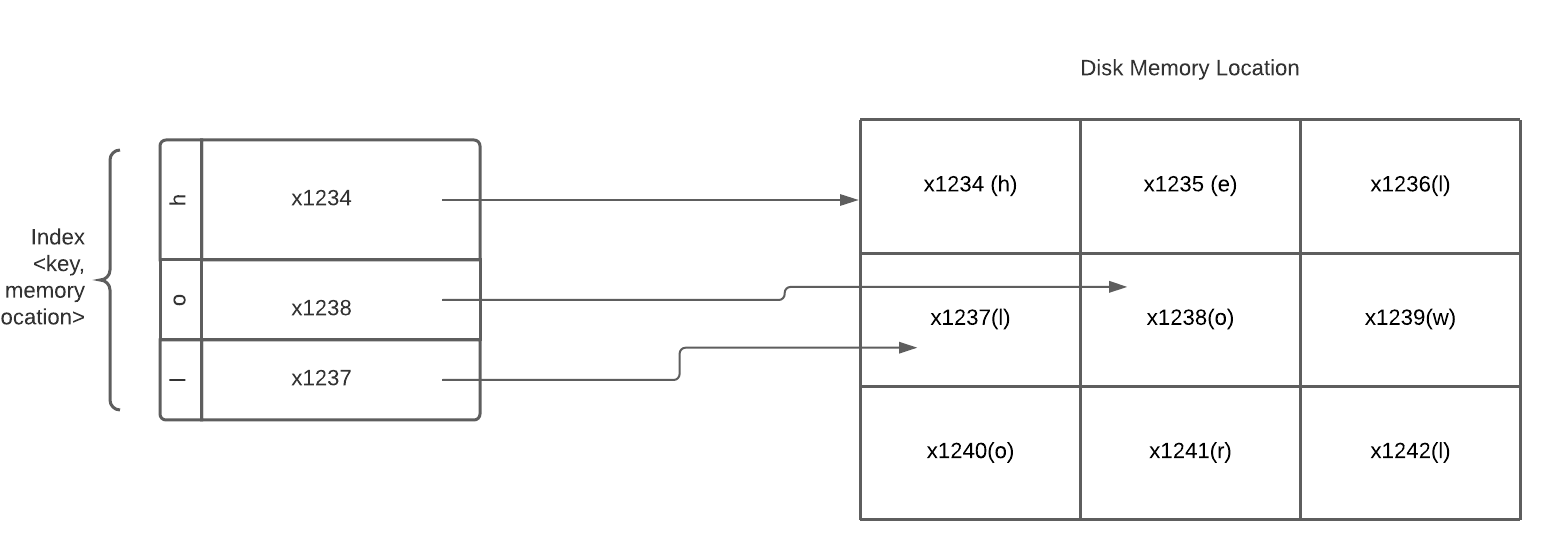
The data is packaged in segments, where the most recent write will always be in the most recent segments. If you want to read from a disk, you will need to start from the most recent segments and traverse backward. Therefore, read will be a linear time. To speed up the read, you will need to have some sort of index.
There are a couple ways to create an index. You can create an in-memory hashmap that stores all the keys you want to query and value that point to that absolute value’s memory block. For instance, if you store a big file of text in the disk - let’s say that each character occupies a storage block. A text file like “Hello World” will occupy 11 blocks. The key, in this case, can be the character, and the value will be the location of that block. This is how Bitcask (the default storage in Riak) is implemented with its key-value NoSQL database.
How about storage space? Since we always append on write to disk, there is a possibility that we will use up a lot of space in our disk. How do we avoid eventually running out of disk space?
A good solution is to break the log into segments of a certain size. When that segment is full, we can write our next data into a new segment file. Moreover, we can also perform compaction on these segments to merge the two segments together, throw away any duplicate keys in the log, and keep only the most recent update for each key.
In brief, when performing a write operation, the algorithm will just append the data at the segment and create a key on that data that points to the location. If the data reaches the maximum segment size, the algorithm will write the new data to the new segment. The most recent segments represent newer data, and the older segment represents the older data. When performing read, the algorithm will go through the most recent segments first - go through each key and search for a key associate with that search. If we cannot find the key associated with the newest segments, we will scan the key on the next older segment. While all these operations, the algorithm will perform compaction on these segments to merge the two-segment together to safe space.
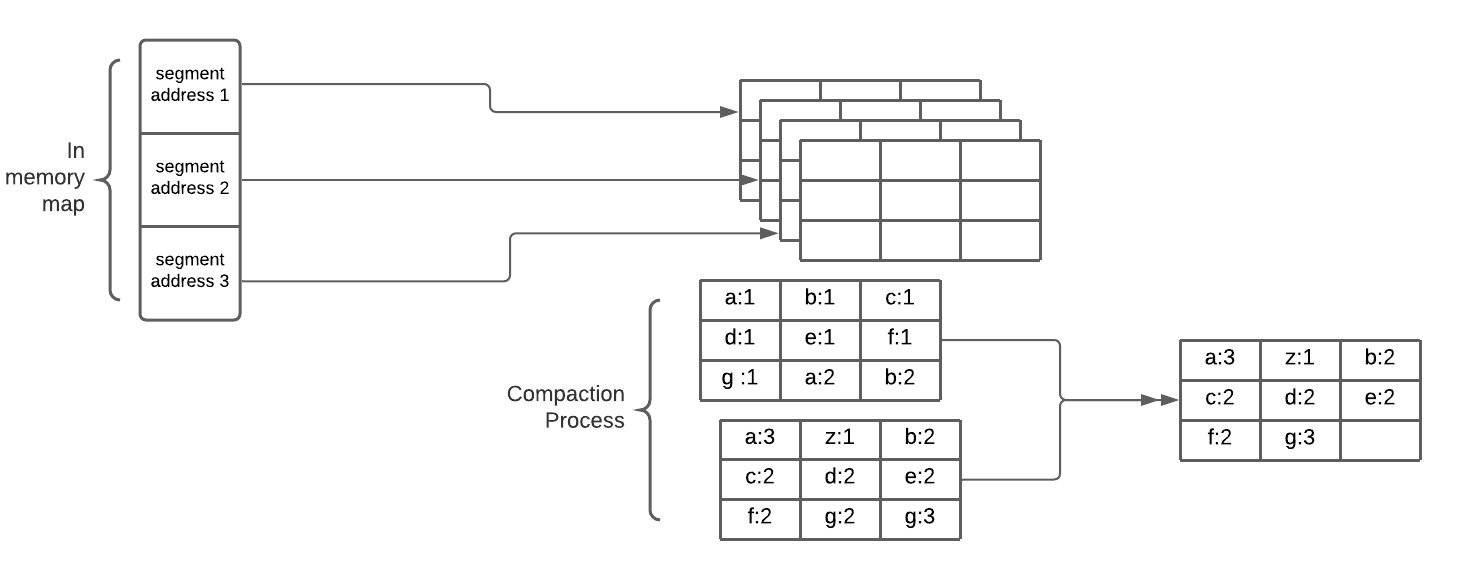
There are a couple of ways of optimizing log-structured storage. For instance, since log-structured storage segment is a sequence of key-value pairs. These pairs appear in chronological order, meaning the value gets append later will appear later in the position of the key. Technically, this doesn’t really need to happen, and we can make the key sorted through the compaction process. This kind of format in the log-structured storage is called Sorted String Table (SSTable). We can have a sparse index in our memory hash map to save space with this kind of structure. LSM Tree persists data to disk using the SSTable format.
Advantages of Log-Structured Segment Storage Engine
One of the advantages of a log-structured storage engine is that the value is that it is append-only. The design pattern of append-only may seems like it is inefficient at first. However, there are a couple of reasons why this design pattern can be advantageous. First, having a sequential write operation to disk is generally much faster than random write on disk. As I often preached about Immutability, dealing with concurrent read and write is much simpler if segments are immutable.
Because of a sequential write operation and an SSTable format, each data segment can be compressed better because each segment is closed. Further, a log-structured storage engine doesn’t need to have any space overhead for the additional space due to fragmentation.
Disadvantages of Log-Structured Segment Storage Engine
If in the middle of updating the value in B-Tree, the server crashes, it can result in corrupted indexes - a child that is an orphan. Therefore, most of the B-Tree designs will write to a write-ahead log file before doing any further operation to provide reliability in the storage system. For this reason, writing to B-Tree often will write to multiple sources and thus slow down operation compared to LSM Tree.
There will always be a space overhead in B-Tree because we want to leave some space for dealing with fragmentation.
Updating values in a concurrent environment in B-Tree is quite complex - you will need to have careful concurrency control to avoid any inconsistent state in the tree. Usually, we protect the tree data structure in latches (lightweight locks) when updating or accessing B-Tree.
Real-World Usage
LevelDB, RocksDB, Bitcask, and Google Big-Table use a log-structured storage engine. Cassandra supports both log-structured and B-Tree. However, this article mentioned the basic algorithm requires for you to know these storage engine characteristics. They are other optimization in each of these storage engines for reliability and resiliency, and I will not talk about them in this post.
Page-Oriented Storage Engine (B-Tree)
A page-oriented storage engine is more common than a log-structured storage engine. One of the indexing structures in a page-oriented storage engine is B-Tree.
B-tree is similar to SStable in that it has a key-value pair that is sorted by key. However, B-Tree follows the structure of putting data based on 4KB size pages or blocks. This structure mimics the underlying hardware - disks are also arranged in terms of blocks.
Like tree data structure where the branch can serve as a pointer that points to the next node in the tree, each block has several addresses that identify another block’s location in B-Tree.
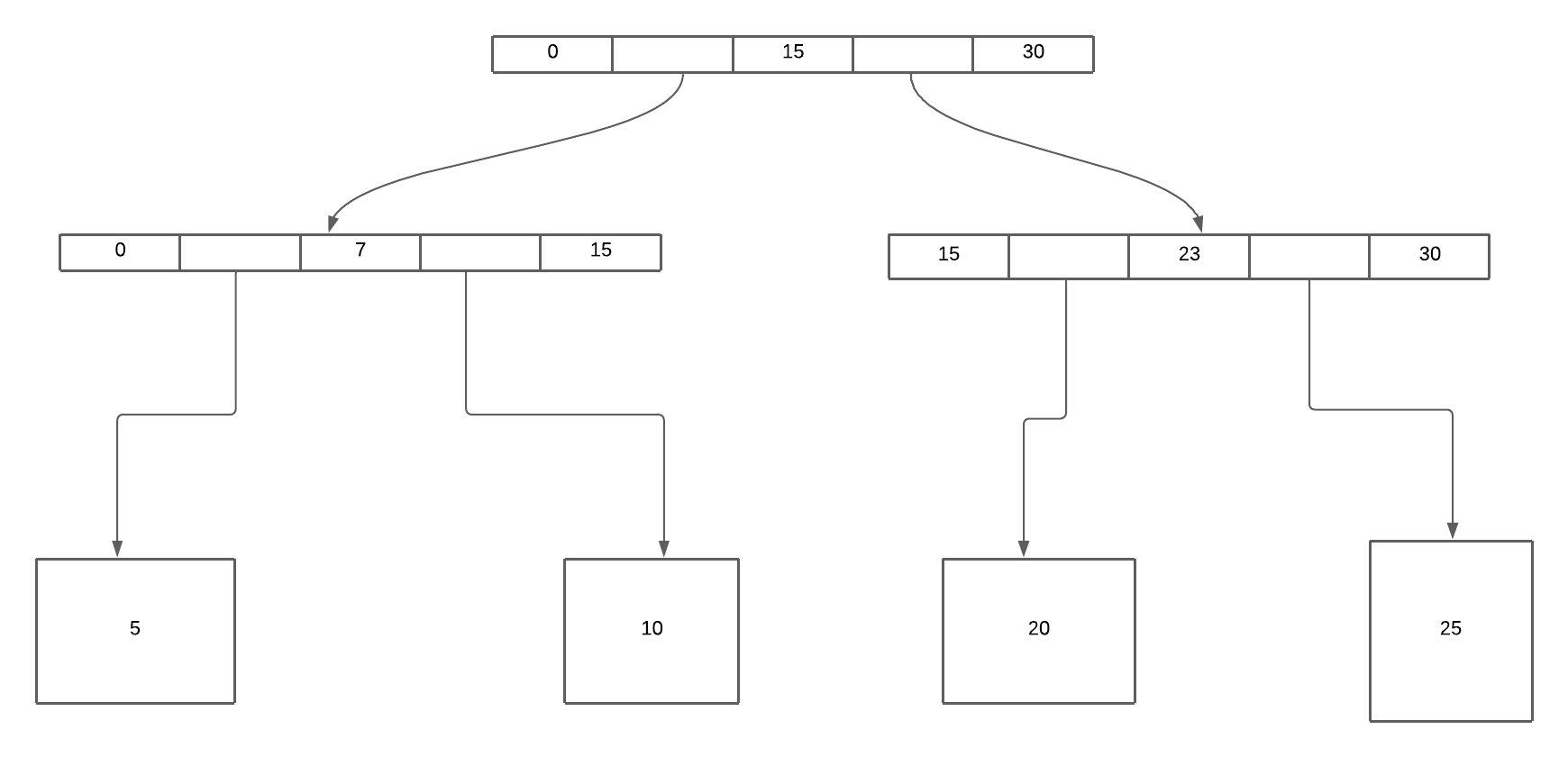
Usually, the root and each of the intermediary nodes in B-Tree is a pointer, and the B-Tree leaf will be the value of that location. Each child page is responsible for a continuous range of keys.
When performing read, starting from the root page, check if the items are within the key value range. If the items are within the range, traverse down to the child page on that reference. Recursively going down until you hit the leaf page.
When performing write/update, B-Tree took the approach of updating and writing the value in place - searching for the leaf key, then changing that value on that page, and writing it back to the disk. If there isn’t enough space to accommodate the new key, it creates a new page and updates the parent’s pointer to point to that new page.
Advantages of Page-oriented Storage Engine
Because B-Tree is organized in a tree-structured, and the algorithm ensures that the tree remains balanced, we can assume that readers will just need to go down into the depth of the tree.
Reading data can be advantageous because it only takes O(logN) time. Most data can fit into B-Tree with 4-5 levels deep.
There are many innovations within B-Tree since it is a more mature storage engine than a Log-structured storage engine.
Lastly, since the key exists only once in B-Tree, it is very attractive to create databases that offer strong transactional semantics. Therefore, many relational databases internal storage engines are using B-Tree.
Disadvantages of Page-Oriented Storage Engine
If in the middle of updating the value in B-Tree, the server crashes, it can result in corrupted indexes - a child that is an orphan. Therefore, most of the B-Tree designs will write to a write-ahead log file before doing any further operation to provide reliability in the storage system. For this reason, writing to B-Tree often will write to multiple sources and thus slow down operation compared to LSM Tree.
There will always be a space overhead in B-Tree because we want to leave some space for dealing with fragmentation.
Updating values in a concurrent environment in B-Tree is quite complex - you will need to have careful concurrency control to avoid any inconsistent state in the tree. Usually, we protect the tree data structure in latches (lightweight locks) when updating or accessing B-Tree.
Real-World Usage
The default storage engine for relational databases follows the B-Tree architecture. Some of the NoSQL databases use the B-tree engines, such as the latest storage engine in MongoDB, WiredTiger, which supports both LSM Tree-based and B-Tree-based.
When to use Log-Structured Segment Storage Engine vs. Page-Oriented Storage Engine
Log-structured storage engines are typically good for write-heavy applications. As mentioned above, the sequential write operation’s advantages and no space overhead make writing value fast to disk.
Reads are typically slower on LSM-Trees because they have to check several different data structures and SSTables at different compaction stages.
Page-oriented storage engines are typically good for read-heavy applications because of how the algorithm ensures read is in logarithmic time.
At the core, a modern database storage engine uses an index management algorithm optimized for either read or write performance. The database API layer, such as SQL or NoSQL, is independent of its storage engine since LSM and B-Tree are implemented in SQL and NoSQL.
However, at the end of the day, your team will need to benchmark both storage engine performance with your particular workload to know which storage engine is suitable for your applications.
Closing
By going through two families of the storage engine behind modern database storage, you know why there is no perfect database that can fit all applications. These architectures are designed to solve certain problems in our applications. The general rule of thumb with these storage engines can be classified in RUM conjecture. You can check out my previous article if you want to know more. However, RUM conjecture is similar to the popular CAP theory where you can only have two of the three, but not all three.
Now, you know why Cassandra is good for write-heavy applications or why SQL can perform well on transactional operations. You know what family of storage engines these databases are classified as. Further, you can read more on other attributes provided by these databases and identify if your team should adopt them.