Designing a Database application is the first thing we usually do when we want to start working on an application. Data is at the core of these applications, whether a simple Todo app with React and NodeJs or a complex monitoring application for microservices.
Designing a good data model can help you write more performant software, and there are also fewer hacky steps that you need to do when extending a new feature.
One of the popular databases in the modern application is DynamoDB. DynamoDB is popular because it was designed for enormous, high-velocity use cases, such as the Amazon shopping cart. Thus, it can’t tolerate the inconsistency and slowing performance of joins as a dataset scales.
Although DynamoDB is performant, designing a data model in DynamoDB is tricky. For instance, we cannot think about how to normalize the data to avoid anomalies because DynamoDB is a NoSQL database.
These are the major difference that I realized when designing data model in DynamoDB:
Design Based on Access Pattern
In SQL, designing models are based on database normalization. We design our data according to these laws, first normal form, second normal form, and third normal form.
However, understanding access pattern is key when designing a data model in DynamoDB. For instance, we design our partition key and sort key based on how the user usually seeks operation.
No Joins
One of the benefits of joins is getting multiple heterogeneous items from a single request.
In a NoSQL database, data are no longer normalized. You may need to duplicate the attribute on multiple items(row). There is no such thing as “join” when performing a query. We often said it is one of the disadvantages of using NoSQL storage. Thus, “join” often moves into the service level.
Creating a data model on NoSQL based on the Entity-Relationship diagram will not work, and there are different ways of thinking about data modeling in DynamoDB.
One Table Design
One table design is to put all your entity and your data model in that one table. It is a design pattern that is hard to grasp for people who are comfortable with relational design.
There is no joining in DynamoDB because joining cannot tolerate their performant use case; yet, a common way to model data in DynamoDB is to apply relational design patterns. They put their items in a different table and do joins on the application level. This “joins” operation becomes the bottleneck as Network I/O is the slowest and cannot perform in a concurrent environment.
One tip of designing your model in your DynamoDB is to have the application handle as few requests to DynamoDB as possible - ideally one.
We need to figure out the best practice and steps to design our data model with these constraints. I want to show a three-step process of transforming relational model design to fit DynamoDB collection with a side-project example that I am currently working on, the Medium Publication Index.
What is the Access Pattern of your Application
Before we start thinking about all the entities in this application, what is the access pattern for this application?
The access pattern is pretty much anything that you think about how the user accesses your data.
These are the example access pattern that I think the user wants to do when they want to retrieve the Publication Index (to name a few):
- User should be able to search the metadata of that publication name
- User should be able to search all articles within that publication Name
- User should be able to search all tags within that publication Name
Once we write down all the access patterns, we can go to the next steps.
Design your data with Relational Data Design
Design the entity of the model with relational data design. Design the data based on flexibility and normalized it. Identify each relation of the entity, such as one-to-many, many-to-many relationship.
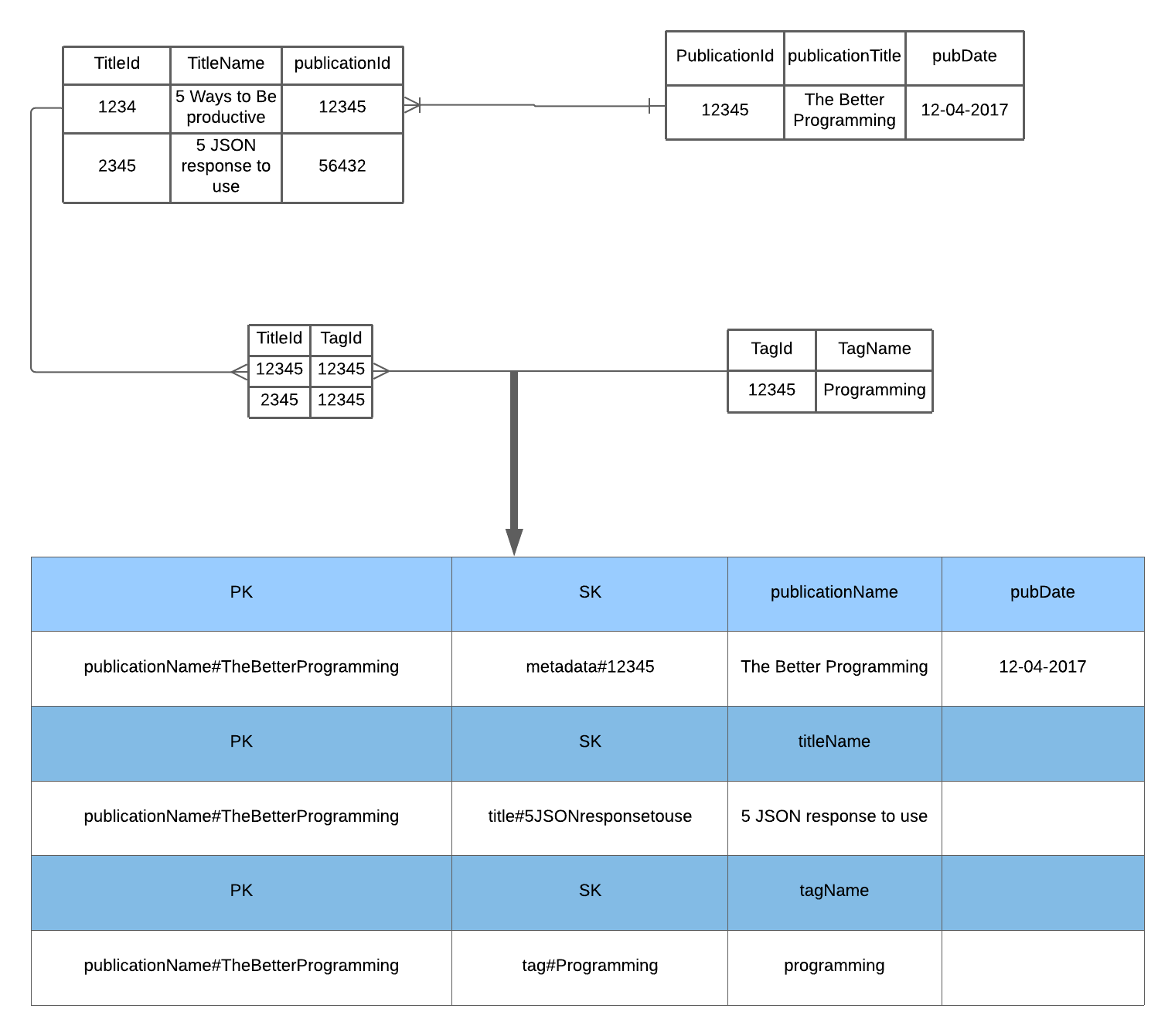
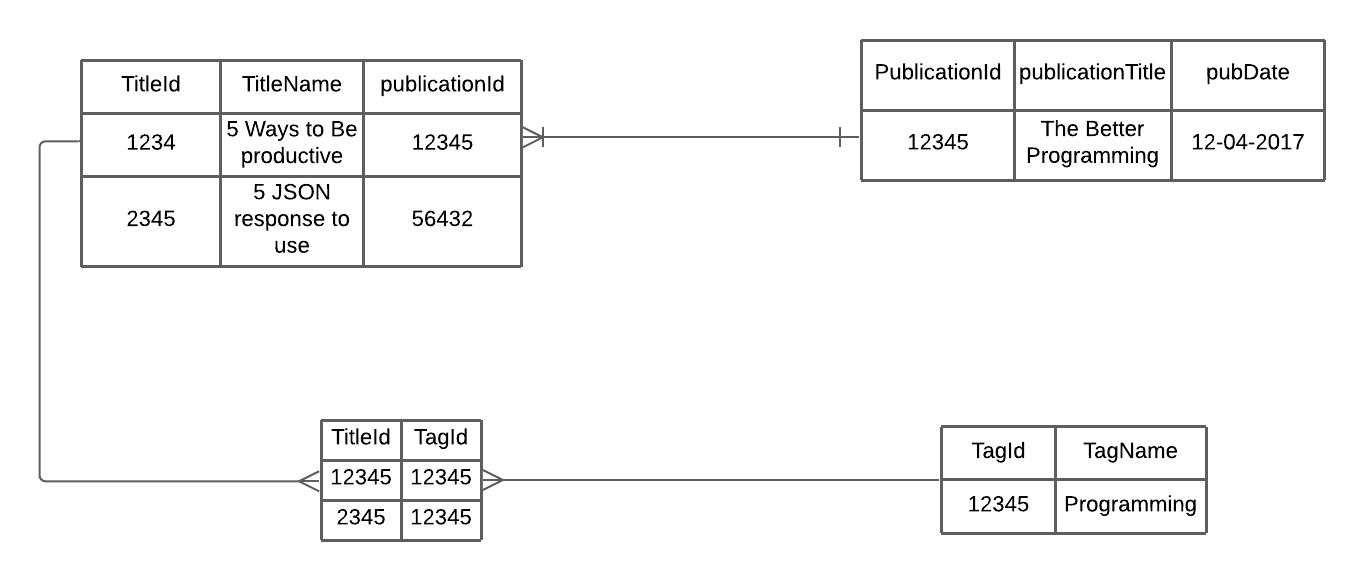
In the example of the Medium Publication Index, publication and title are one-to-many relationships, and title and tags are many-to-many relationships. Each publication will have many articles. Each article can be in many tags, and each tag can also be in many articles. Therefore, if we want to design this in a relational database, we will have four tables: publication, articles, tags, and a join table for articles and tags. Articles contain a foreign key that associates with publication. The join table contains tagId associate with titleId.
Defining Partition Key, Sort Key, and GSI indexes
Based on the previous two-section sections, we can start defining our partition key and sort key. Since our model is hierarchical, it mimics very similar concepts to a Map.
In DynamoDB, each item requires a partition key. If the partition key is not unique, you require to define the sort-key.
There is a couple of design pattern to design a one-to-many relationship model in the database. I usually use the common pattern to use a partition key that serves as the root of the hierarchy and sort key as each entity’s primary key.
In the example above, we won’t have any meaningful names on our partition key and sort key. Therefore, let’s define the partition key as PK and sort the key as SK. Since publication is the root of the hierarchy model, the partition key will be the publication’s name. The sort key can be the unique Id of three of the entity.
Remember, we are designing our table based on an access pattern. The relational data design helps guide us what the partition key, sort key, and any additional global secondary indexes if we need to. That doesn’t mean we need to emulate many-to-many relationships like the relational data design. It is okay if our data is not normalized.
We will create the PK and SK values with [EntityName]#[EntityValue]. For example, the partition key will be PublicationName#TheBetterProgramming, and the Sort key can be Metadata#[PublicationId], Title#[TitleName], Tag#[Tag]:

A note here is that I didn’t try to have a many-to-many relationship for title and tags because of this application’s access pattern in part one.
Publication is the partition key because we can observe the three access patterns at step one and know that all the values are search based on the publication name. Therefore, the design can create these access pattern in our table:
- Retrieve a publication: use the GetItem API call and the publication’s name to request the item with a
PKofPublicationName#<PublicationName>and theSKof#Metadata#[PublicationId] - Get all titles (tags) in that publication by using a Query API action with key condition expression of
PK=PublicationName#<PublicationName>andbegins_with(SK, "Title#"("Tag#")). It will retrieve the publications and the title without fetching all the Publication objects and all the tags.
We also noticed that the model is hierarchy-based because each query is based on the publication first.
Another pattern is to use a composite sort key pattern. However, this pattern is more suitable when you have more than two hierarchy levels, such as addresses. You want to have an access pattern for different levels within the hierarchy, such as query all cities in this country.
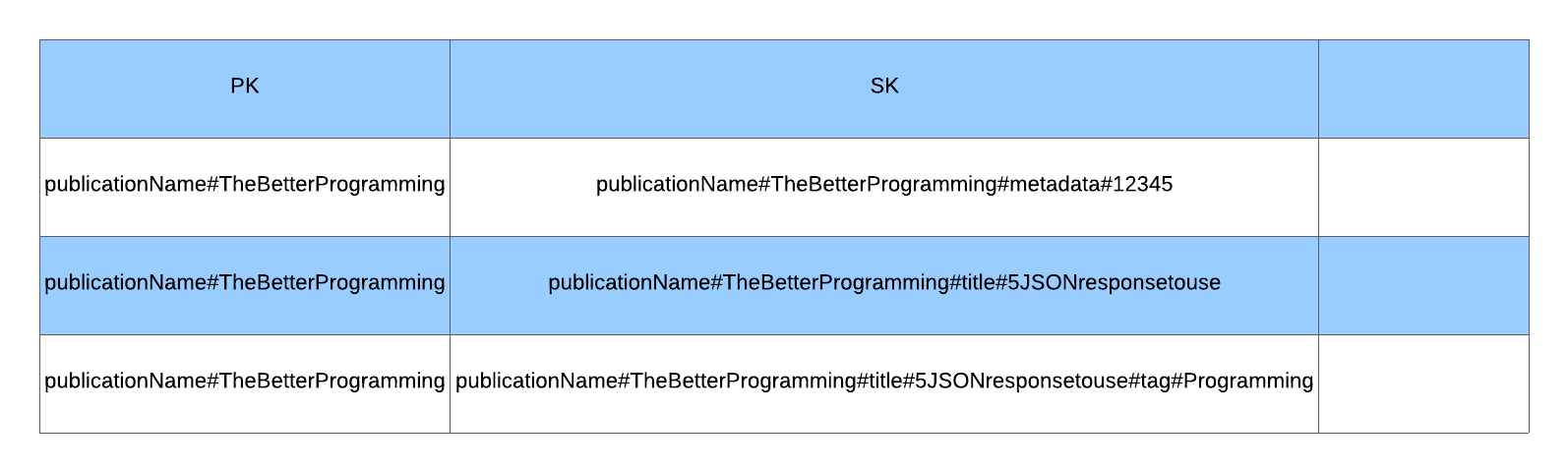
We will transform publication model above into composite sort key pattern for illustartion. Instead of having a partition key as PublicationName#<PublicationName>, we have a UUID for the partition key, and the sort key will be:
- publication name:
PublicationName#<PublicationName>#Metadata#<PublicationId> - title name:
PublicationName#<PublicationName>#Title#<TitleName> - tag: ``PublicationName#
#Title# #Tag# `
We can have a couple of access pattern, such as:
- Retrieve a publication: use Query API with the key condition expression of
begins_with(SK,PublicationName#<PublicationName>#Metadata) - Retrieve all titles in Publication: Query API with the key condition expression of
begins_with(SK, PublicationName#<PublicationName>#Title#)
However, we need to use FilterExpression to return all the tags within the publication. Also, we need to use FilterExpression to get all the publications without the title and the tag.
If you noticed, putting the tag field as a sort key Title#[TitleName]#Tag#[TagName] on the above scenario may jam all the title name and the tag name together when searching.
Another pattern is to create a Global Secondary Index. Create a Global Secondary index with a partition and sort key different from those in the base table.
This scenario is good if you have more than two levels of hierarchy in your model, and you don’t want to jam the second and the third entity together as the sort key.
Let’s illustrate with the example above. The first example of using the regular sort key is that we cannot retrieve all the title tags.
We can create an additional attribute in a tag called GSIPK that will name the title. Therefore, we can query all the tags in the title.

Closing
In RDBMS, you design for flexibility without worrying about the implementation details or performance because the query optimizer does all the implementation details. However, DynamoDB schema design is based on how the application access pattern.
DynamoDB doesn’t have a joins operation like SQL. Therefore, it pre-join the data using item collections to fetch all required data. With this kind of design, it is encouraged to adopt the single table design.
One of the initial steps in designing schema in DynamoDB is to understand the application’s access pattern. Then, design the data based on the relational data model. Finally, I used the previous two solutions to identify the partition-key, sort-key, and other global secondary indexes.
If you are interested in learning more about all the design pattern of DynamoDB, check out these resources: