Imagine when you are trying to transfer 100 dollars from account A to account B, and both accounts are in the same bank. After you initiate the transfer, you refresh your screen. However, when you refresh your screen, your total balance dip - that 100 dollars seem to vanish out of thin air. You see that account A is 100 dollars less. However, account B is not 100 dollars more. Then, you refresh the screen a couple of times to see that account B has gained 100 dollars.
This problem that you experience during a transaction is called read skew. An anomaly happens when you read the transaction at an unlucky time - during and after a written transaction.
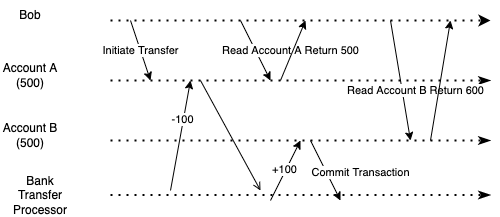
It may be a bad user experience, but this will not cause any problem if you refresh the page after the successful transfer transaction.
However, read skew becomes a problem when doing a database backup or analytics query.
In database backup, we need to make a copy of the database. There may be a written request during the backup process coming in. If the read skew inconsistency happens, the backup result may be inconsistent. Some data are in the old version, and other data are in the new version. This inconsistent problem may become permanent with such an operation.
We need to scan over a large database in an analytics query and periodically check for data corruption. Read skew can cause the search and check to be inconsistent - often may have inconsistent results and fire off false alerts about data corruption.
Solving Read Skew
The problem with reading skew is that a read transaction is read one time in the old database version and another in the new database version.
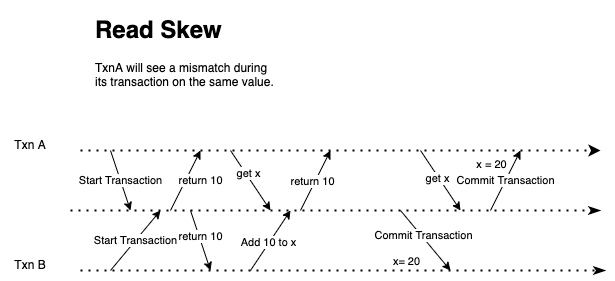
The important point here is that the read transaction needs to be consistent - it doesn’t need to be the up-to-date version. It needs to be consistent from the beginning of the transaction until the end, so we need to keep the data version the same.
For instance, if Bob is running the read transaction at the data version 1, throughout that transaction, Bob should only be able to read the database data version 1. If in the middle of the transaction process, a new write transaction occurs, which will update the data in the database. Bob will not see that new version in his transaction.
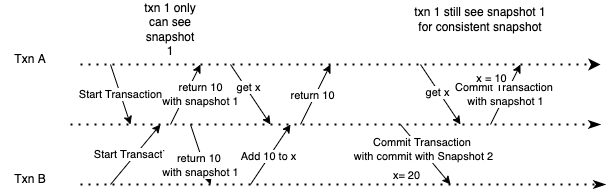
Hence, we can make the transaction read from the consistent snapshot of the database - the transaction will see from all the data that other transactions committed in the database at the start of the transaction.
This feature is called snapshot isolation, and it is offered in a lot of relational databases, such as PostgreSQL and MySQL.
Implementing Snapshot Isolation
We need to keep various snapshot versions in the database to implement snapshot isolation. Each time the beginning of the transaction, the database will give the latest committed snapshot version to the transaction. Then, the database will keep track of each transaction with its corresponding snapshot version to keep the read consistent.
Each transaction has a transactionId, and the transactionId is retrieved from the database. Thus, the transactionId is always increasing. The database keeps track of each transactionId written to the database using createdAt and deletedAt values. The database created a tag on that operation with the transactionId from the transaction after the transaction is committed. The database further makes a snapshot of the new transaction and tags that snapshot with the latest transactionId. When a new transaction reads from the database, the database retrieves the latest committed transaction before the transaction with the following several rules:
- Any transactionId that is currently not yet committed to the database will not be shown even if the subsequent transaction is committed.
- Any aborted transaction will also not be shown.
- The database will not show any transaction with the
transactionIdlater (bigger) than the currenttransactionId. - The database will show any other transaction to other incoming transactions reading the database.
Let’s take a look at what happens in Bob’s scenario:
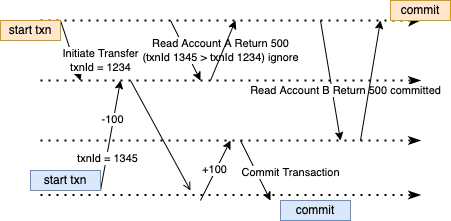
- When Bob initiates its transfer transaction, it kicks off a background process to transfer 100 dollars from account A to account B. This transaction will first call the database or aid service to get an incremental
transactionId, and initiate the transaction - let’s say the transaction is 1234. - The subsequent read transaction will need to do the same by getting an incremental
transactionIdand calling a read request to the database - let’s say thetransactionIdis 1345. - While the transfer is not yet finished, the database will not show Bob the data applied by
transactionId1234 (rule number 1). - If another write transaction was initiated after
transactionId1345, because that transaction has a biggertransactionId, the database will not show that transaction totransactionId1345 (rule number 3).
During delete, instead of deleting the value in the field right away, the database will mark a tombstone on that field. One reason for not deleting the value right away is that those earlier transactions may still use that value. Thus, we can leverage garbage collection to check and delete the value asynchronously once all transactions use the value committed to their transactions.
Taking Snapshot Isolation to Distributed Environment
So far, we have explored how to solve read skew in a single node environment - we assume that databases are not distributed across multiple clusters.
How can we expand snapshot isolation in a distributed environment?
It will be hard to get a global, ever-increasing transactionId in a distributed environment. For one reason, each machine that potentially resides in a different database may have its UUID counter, and we need to have some coordination to ensure causality. If transaction B reads the value from transaction A, we want to ensure that transaction B will have a bigger transactionId than transaction A. How do we deal with a consistent snapshot in a replicated database?
Can we use the clock or time of the day as a transactionId to write to the database? Time-of-the-day clocks are unreliable, as NTP synchronization is based on unreliable networks. Therefore, some machines may have clock skew, arbitrarily moving backward in time. The time of one node may also be different from the time of the other node. However, if we can make the clock accurate enough, it can serve as a transactionId - the time later on the clock means that the events are produced later. How do we ensure that the clock is accurate enough for transactionId?
When retrieving the time-of-day values in each machine, we want it to return a confidence interval, [Tbegin, Tlast] instead of getting a single value. The confidence interval indicates that the clock has a standard deviation of plus or minus a range of Begin and Tlast. If two transaction, transactionX, transactionY coming in, [TbeginX, TlastX], [TbeginY, TlastY], and TlastX < TbeginY. We can ensure that transactionX is earlier than tranasctionY. However, if the value overlaps, that is where we cannot determine the ordering. This approach is used by Google Spanner to implement its snapshot isolation. Spanner will deliberately wait until it is over the previous transaction’s confidence interval not to overlap to commit the current transaction. Thus, they will need to keep the confidence time interval of each clock on the machine as small as possible to avoid latency. Google deploys an atomic clock or GPS server on each data center to allow clocks to be synchronized.
To ensure that the snapshot is the latest on each database replica, we can use quorum strategy to get all the latest transaction snapshot from all of its database clusters. Another strategy we can use is to ensure that the transaction always routes to the same database instance to have consistent snapshot results.
Wrapping Up
Read skew happens when you didn’t see a consistent result from reading the database data because another write transaction occurred in the background. A consistent snapshot is a solution to read skew in a single-node database.
A consistent snapshot is an isolation level that guarantees that each transaction will read from the database’s consistent snapshot, usually the most recent snapshot before the current initiated transaction.
Implementing snapshot isolation requires a monotonous increasing counter, transactionId, to determine which version to return to the transaction call. However, this can be tough when dealing with a distributed environment because coordination is required to generate causality. One solution to solve this is by using a time-of-day clock that returns a confidence interval to create an ever-increasing transactionId.
Lastly, to ensure each transaction gets a consistent snapshot, we can use the quorum strategy to always return the most recent snapshot from the current transaction returned by the majority of the node or to have session affinity on transaction calls and database instances.
How would you ensure read consistency in a distributed system? How would you solve the creating a global transactionId? Comment them down below!