A lot of our applications nowadays center around API. For instance, a lot of the core of our application code communicate through API. We built applications by layering them with an understandable abstraction. This abstraction layer is essential because it helps us solve how our software is written and its problems.
There are two popular ways of defining API - imperative and declarative. SQL is a declarative query language, whereas IMS and CODASYL query database using imperative code. The most commonly used programming language is imperative.
However, in this article, one of the big reasons declarative API is more widely used is that it is more concise to work and provides better abstraction than the Imperative API.
Imperative Declarative In Data Model
Before there are SQL, in 1960, IBM designed IMS (Information Management System) with a hierarchical model called CODASYL, similar to the JSON model used in the document database.
This model is called the network model, which helps create a data model for many-to-many relationships. Every record will have multiple parents, and the way we mark one record in relation to the other is by using a pointer in programming language instead of a foreign key.
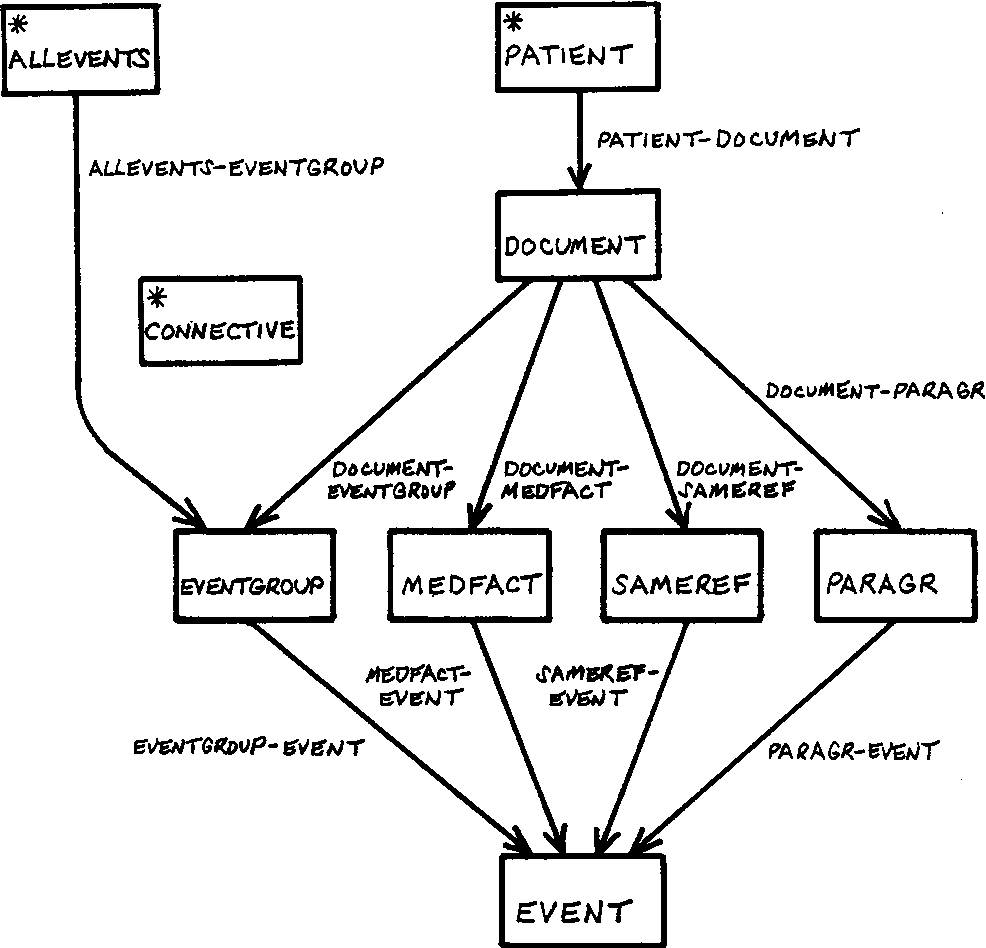
If you want to get the value of a specific link, we have to traverse from the head of the list and look at one record at a time until you find the one you want.
This way of retrieving data makes it hard for developers to make any updates or changes because they have to keep track of all the relationships, the parent of the link, along the way - or else they cannot find the data that they want.
How Relational Model Data Query is Different
The relational model uses a different way of querying data. We as a developer will tell the program “what” to do, instead of “how” to do it. Therefore, the query optimizer will decide automatically decide which part of the query to execute in which order and which indexes to use.
One benefit of the declarative approach is that the query language abstracts the client’s implementation details using the API. This can leave room for optimizing the query optimizer to optimize better performance and introduce newer functionality without any query changes.
As more computation logic is shifted towards software instead of hardware, SQL becomes more popular and widely used because of its flexibility.
Let’s look at another analogy and illustration of declarative API and imperative API from the web browser.
Web Service as an Illustration
Let’s take an example of manipulating DOM elements using the declarative and imperative approach in a web browser.
In general, using CSS is declarative and manipulating DOM elements with javaScript is imperative. In the example below, you can see why CSS is much better at querying data on the web than javaScript.
Changing the color of the text in paragrah The one who got away on the HTML tag below that looks like this:
With CSS, your code will look like this:
Relatively simple, as it declares the pattern of elements to which we want to apply the text’s blue color. The paragraph, <p> tag that is not under the class name topClass will not change color because it doesn’t match the declaration.
On the other hand, using JavaScript to manipulate the DOM element will look like this:
Using JavaScript to manipulate the DOM elements, we have to tell the program how to do it. It doesn’t have the abstraction of telling the program what we intent the result to be. This code is not much longer than CSS but also harder to understand. The new developer will need to fully follow the HTML page’s instructions to understand the function’s intent.
Besides, we have to keep track of what we set on the DOM node, and we don’t put it on the DOM node. For example, if the user goes to the next page, we need to manually know how to set the color:blue back to black. Moreover, if there is a change in the API, such as a new function, getElementByTagNameV2 (I’m just naming something up), the client will need to rewrite the function because the API is tightly coupled with the implementation of the client.
On the other hand, in the declarative way of defining API - we can have browser performance optimization without having the client change any of the CSS tags that they wrote.
We know that CSS is much more flexible easily backward-compatible than JavaScript in querying data in a web browser like how SQL is CODASYL.
In Practice
Ultimately, the higher the abstraction you reach for your API, the more declarative your API will be. All low-level API exposes the verb you want to call, and we cannot encapsulate a higher-level abstraction API without having the imperative API. In other words, an imperative API needs to exist to encapsulate the API into a declarative one.
If you want to make your API more declarative, put config on your API for further abstraction.
Usually, declarative API will abstract certain aspects by giving you some fault-tolerant functionality underneath, so you don’t have to account for that.
Let’s say you want to create an abstraction on polling value from a queue. You can mention the mechanism of polling by giving a function poll(). In the imperative way of declaring poll(), it will just do that one thing - poll. If there is some network issue or failure during the process, it will just throw an exception. A declarative way of writing an API is to mention a configuration on the function’s intent. For instance, saying a retry count of 2 and what sort of action you want it to have if it failed. Any specific error handling or functionality that the client needs to account for can encapsulate those in a config value that lets the API do all the hard work for you.
Closing
We get to see why declarative API is much easier to understand and work with than imperative API. First, we know the query language that is currently widely used - SQL, and how it compared to the predecessor CODASYL. Then, we see how querying the web browser’s declarative way is less painful than the imperative form. Lastly, understanding your user’s intent and using configuration to abstract all the logic they need to implement is an excellent way to transition to a declarative API.