FIFO queue is a message queue that guarantees exactly-once delivery with no duplicate message on the receiver end. This property sounds simple enough, but it is quite hard to achieve in a distributed system environment.
Nowadays, a lot of cloud technology has abstracted all the distributed system components to terms that we understand. However, even though they may market that their service or message queue is a FIFO queue, there are still certain restrictions to that properties. You cannot solely rely on their service for exactly-once message delivery and FIFO queue and design your system horizontally like the usual because the property may not be held in that environment.
In this article, let’s dive deep into the FIFO queue’s property, and that I walk you through three simple scenarios that break those properties and how you can resolve that. At the end of the article, you can determine if the FIFO queue property can exist in the distributed systems yourself.
FIFO Queue in the Real World
A FIFO queue is a message queue that is in first-in-first-out order. That means any decree of messages that you publish to the message queue will be retrieved in the same order as it was published.
That sounds quite simple to understand. We often learn this in our 101 class about creating a Queue to answer algorithm questions. We realized that the order matters in a first-in-first-out manner. That also implies something - there will be no duplicate message upon retrieval.
Therefore, we can conclude that the FIFO queue’s two main properties are - message ordering in a first-in-first-out manner and no duplicate messages in the system.
Message Ordering
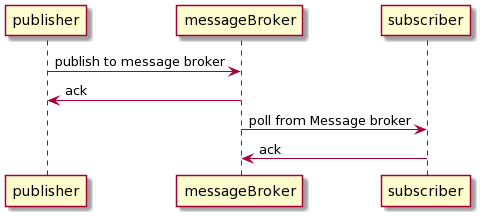
Creating a FIFO queue in a single environment is straightforward. A single publisher publishes to the message system, and a single subscriber subscribes to a message system. The publisher waits until the subscriber acknowledges the message before sending the message to the next value.
In the above scenario, we have a single thread of publisher and a single line of subscribers. We can guarantee that message is in order by some sort of timestamp or sequence id.
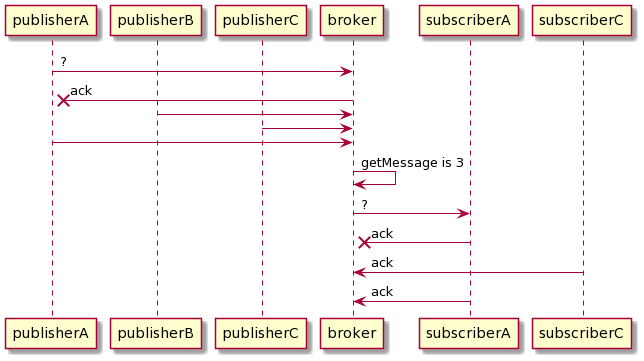
However, in multiple concurrent publishers and consumer environment, message ordering is hard to achieve. Why? Let’s look at the scenario below where we have numerous publishers and a single subscriber, and multiple subscribers with a single publisher.
One scenario that causes messages out of order in a multiple publisher environment is when each publisher publishes to the message broker. The broker usually needs to acknowledge that they have received the message from the subscriber, or else the message will be lost. If the broker server is down, the publisher will usually send messages again to the broker.
Imagine you have 2 publishers - publisher A and publisher B. Publisher A sends a message with a timestamp to the message system before publisher B. When publisher A sends the message to the broker, the broker fails to acknowledge the message because of some internal server error. A couple times pass by, it comes back up. Meanwhile, publisher B sends its message to the message broker. The message broker received messages from publisher B. Then, publisher A sends the message to the message broker again with an interval of retry. We have an order message mismatch.
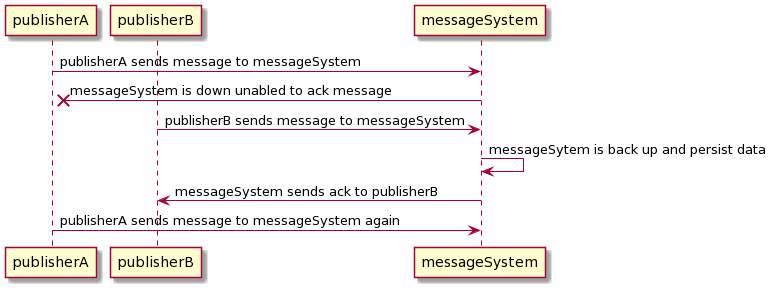
To achieve message ordering, multiple publishers need to coordinate with each other which message to send first. There are two ways to do this: either publisher coordinates with each other to attach a notion of order, or the message system has to secure an idea of order on each incoming system. Either way, we need to have a centralized approach to get the timestamp notion to avoid clock drift and sequence Id to provide consistency. We can have a coordination system such as Zookeeper to coordinate the message’s order delivery upon sending. However, the above solutions mean that we need to limit our throughput to a single publisher at a time.
Let’s look at the receiving end. If we have multiple subscribers subscribe to a queue, there can be a scenario where the message will be out of order. If you have 2 subscribers - subscriber A and subscriber B. After subscriber A acknowledges the message it polled from the queue, the instance died. Meanwhile, subscriber B received the next upcoming message from the queue, accepted, and processed it. Once subscriber A is back up, it processed that message. In this case, the system violates letter ordering properties.
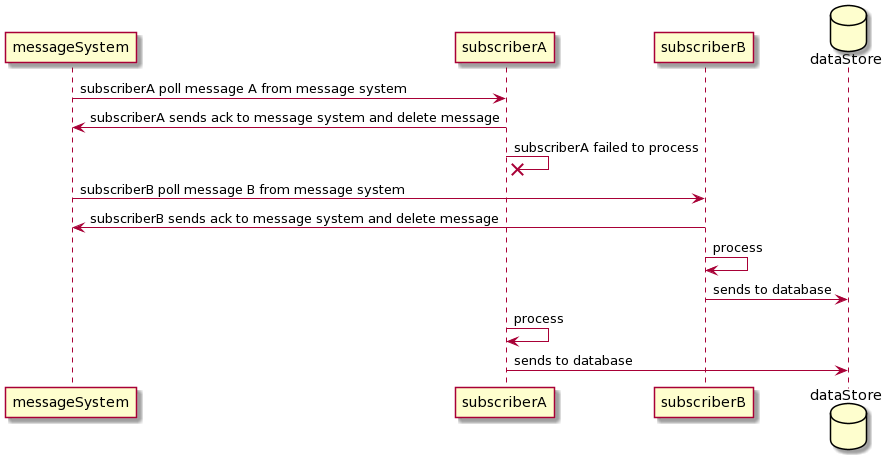
We can also use the same solution as the publisher scenario, where one subscriber will wait for the previous subscriber to finish processing before it polls the next message. In this case, we also limit our throughput to a single subscriber at a time.
From the above two illustrations, we know that the solution to create message ordering is to limit throughput to a single publisher and subscriber one at a time. Suppose multiple threads of publisher asynchronously publish to the same message system. In that case, there is no meaning of order. The message showed up in the queue depending on when the publisher is scheduled. On the subscriber end, we need to process the queue one message at a time to avoid any sort of misordering.
Exactly Once Message
To have an exactly-once message, we do not want to duplicate data in the message system. Let’s look at the synchronous environment’s perspective and dive into multiple publishers and subscriber scenarios.
Duplicate messages can rarely occur in synchronous environments. The publisher can publish one data at a time; publish the next one once the previous one is received to ensure no duplicate data in the broker. On the subscriber end, we received one data at a time. Therefore, there won’t be any race conditions where information is received by multiple subscribers.
In a multiple publisher environment, we can see how duplicate data can occur in the message system. Imagine multiple publishers publish to the message queue. If the message broker fails to send an acknowledgment to one of the publishers because it was not available, they will retry the system multiple times to avoid message loss.
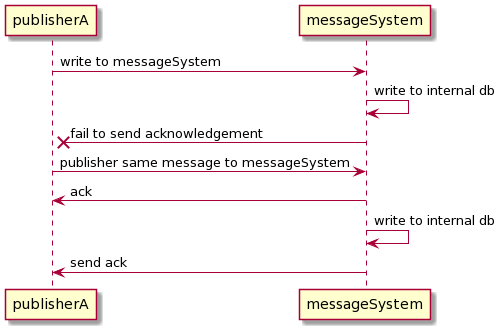
One way to solve this is to create a correlation identifier. The correlation identifier will be the id that identifies its idempotency key on the message. Therefore, if the message system received the same correlation identifier, it knows that it has already been received before. For instance, Amazon SQS has the deduplicationId on a FIFO queue to serve as a correlation id. However, it has 5 minutes expiration time. If the publisher sends the second message 5 minutes after, the message broker cannot guarantee if it rejects a duplicate message.
On the other hand, exactly-once delivery is almost impossible to achieve in multiple subscribers. However, even if you can ensure exactly once on a transport level, you probably don’t want that anyway. If the message broker deletes the message right away once the subscriber received it, there is still a chance of crashing even before the subscriber process the data. In this scenario, you want the message system to deliver the message again.
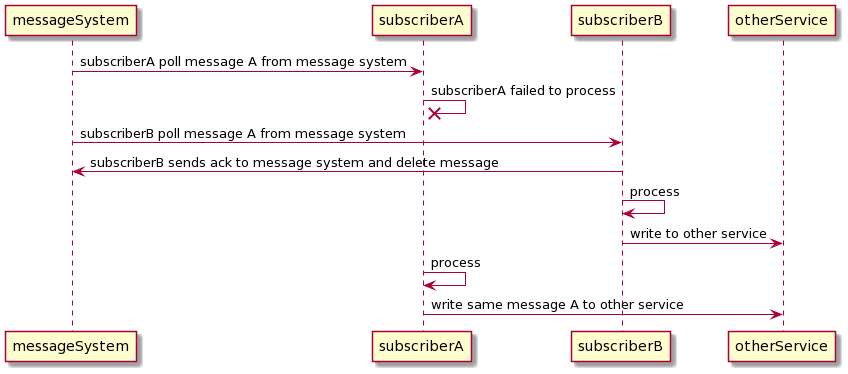
Receiving duplication messages exactly-once processing is possible. Let’s look at one scenario: subscriber A received a message from the broker. Right before subscriber A is about to delete the message, subscriber B polls the broker’s message. Hence, subscriber B will have the same message as subscriber A. One solution to this is to create durable storage on the receiver side. The subscriber can write the incoming message to durable storage during each poll. Once it successfully writes to the storage, it will delete the queue from the message broker. The durable storage will guard against duplicate values. Meanwhile, there will be another message processing asynchronously running background thread to process those messages. This concept is similar to how various database systems use a write-ahead log to store commits.
Closing
FIFO queues in a single environment are straightforward to reason about. However, in a distributed environment, a system can achieve a FIFO queue by having a single publisher publish the message one at a time to provide ordering and create a system that prevents message duplication.
If your design your systems that handle these two scenarios above, then your FIFO queue can exist in the distributed system. If you cannot provide these two properties on your queue, your system cannot do exactly-once processing.
Now, you tell me, can exactly-once processing in whole system event exist?