Microservice architecture can help teams developed applications asynchronously. Teams can deploy their code-based, and it creates a faster iteration and development process overall. However, with flexibility, there is also comes complexity in developing distributed systems. Many of our assumptions in a single system don’t work in a distributed system, and we need to re-evaluate how we approach our design in distributed systems.
One of the examples is time ordering. I recently got to ask how you can ensure the services you created are in the right order.
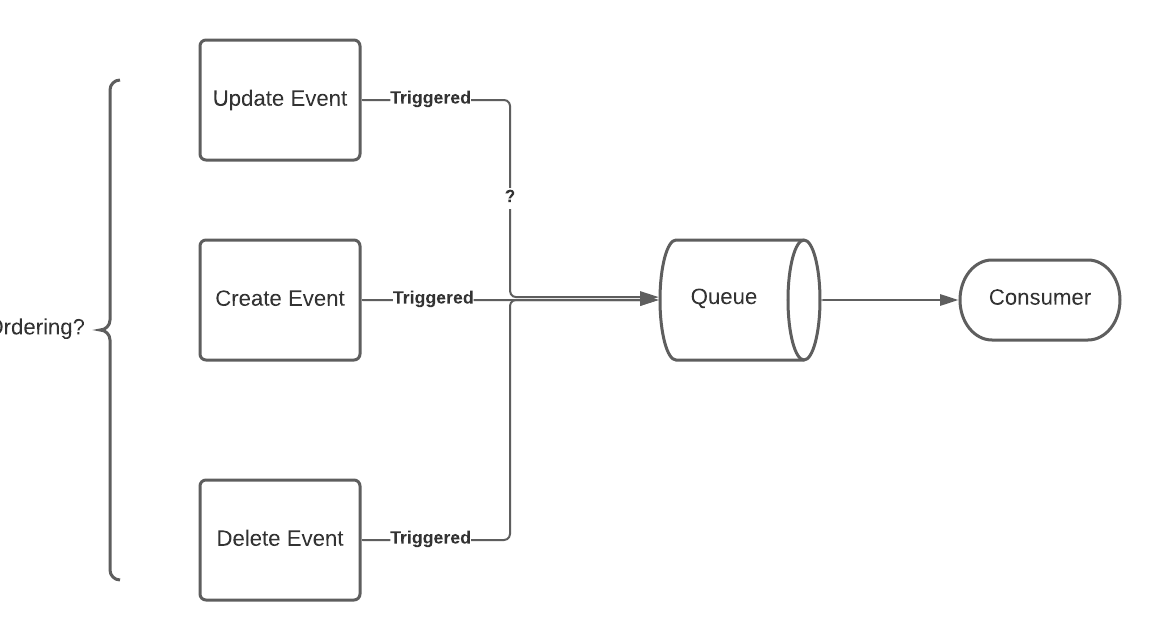
Imagine you created an event-driven architecture with two microservices - Product Service and Order Service.
Product service will be responsible for managing products, and order services are reliable for managing orders. The Product service can emit a createEvent, and update event, and based on the event, the order service consumes the messages through a queue and updates its local data store.
How do you ensure that createEvent can always be before update event?
One simple solution is having the subscriber do a check - if product A doesn’t exist, we can push the value again to the queue, assuming that the createEvent is out of order.
However, if the subscribe received two update events on the same product out of order, that will cause a problem.
We can think that we can create a timestamp on each event, and based on that timestamp, we determine whether or not to do an update on the time. However, this intuition might not be correct either.
What is time?
Time is vital in a distributed system in which it not because we care about what time when a particular event happens in the system, but the order in which the event occurs. Through our assumption, time can help us order things.
Since time can let us observe the chronological creation and update of events, we can tell if A is before or after B.
The notion of time and how it works in the real world is linear. The reason is that we are living in a single unified system, and we all agree on the notion of the timezone and shared clocks (UTC). Therefore, there is rarely any discrepancy when we ask what time it is in a specific location.
Moreover, we think that events usually happen one after another. For instance, event A happens before event B if the time of event A is earlier than the time of event B. In this case, we assume that the exact order of events correlates to the time it happens.
However, this mental model doesn’t work in a distributed system. There is no notion of time in a distributed environment because there is no single truth source (the global clock). Moreover, the events usually happen concurrently (at the same time), and in different places.
Because we cannot determine ordering based on time, it is hard for us to determine if event A happens before event B. Besides, the event in the distributed system doesn’t happen one after another. It can be happening at the same time, parallel, or concurrently.
Total vs. Partial Order
The human level of time is the view as a single system’s model of time. That means, in a single system, since there has one unified clock, the central clock system can place the event in a specific order based on what time it occurred. When we know when every event will happen in a system, we see its total order.
Each node has its local clock in a distributed system, but it won’t know what time it is on another clock on the other node. That node might know how to differentiate the events within that node but cannot order the current event with the events happening on the other node.
Therefore, the state of a distributed system is a partial order, which is neither the network nor the nodes guaranteed on each node’s relative order. However, each node knows its local order.
For instance, if we know that event B occurs after event C, and there is A, B, and C coming in. We see the order of B and C, but A can occur at any time. Therefore, we don’t know the ordering of A. Therefore, a node in the system can’t be sure when the incoming messages occur, and it can’t be sure of when the other node sent those messages either.
If we can only know about partial order, how do we solve ordering events?
Casual Order
Perhaps we don’t need to care about time to order events in our system. The reason why we want to know about ordering is that we want to know which things happen. Therefore, we don’t need to care about the exact time in which the event occurs, but how one event causes another event to occur.
Casual ordering is ordering events not based on when they occurred but based on cause and effect. Through Casual ordering, we don’t need to know when that event happens, but what causes and impact of those events. In that matter, we will know loosely about the ordering of the events.
In the problem above, we can determine if CreateEvent needs to happen before UpdateEvent on the consumer side. However, in terms of both UpdateEvent, we cannot tell which event happens from one before the other.
We can try separating the UpdateEvent to only send UpdateEvent to the queue with an incremented version number or an atomic counter sequence number. On the receiving ends, we can have a data store that stores the version number and will check if the incoming event is more than one greater than the currently existing version in the data store. If it is not, we can use a buffer to reorder or push it again to the queue, assuming it is not in order.
Suppose you are interested more in the casual order. In that case, you can check the logical clock or vector clock to generate partial ordering of events in a distributed system and detect causality violations. If you have any other insights or links in solving ordering problems, please share them in the comment section below.