Leetcode has always been the holy grail to cracking the coding interview. Many engineers have bribe that the technical interview pipeline is broken. Three years ago, a technology company would not have told you to solve two Leetcode hard questions in a single setting. A lot of the technology company right now, such as Facebook, expects you to finish two medium-hard questions - or else you may not go to the next round of the interview.
This interviewing style becomes the race of who can recognize the most Leetcode style questions in one sitting and it doesn’t test on one’s ability and experience to problem solve.
Many companies also realized that having a regular algorithm from Leetcode is not an effective way to examine candidates’ success ability in the workplace. Therefore, some other kinds of interview questions have been created to test a candidate’s problem-solving ability and gauge the experience of candidates.
The Question
Imagine you have a service that needs to do some work and call a third-party API - let’s name it API A. API A takes a long time to compute. Hence, your service should only call API A once.
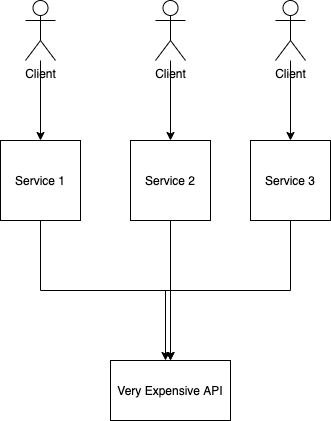
How would you ensure not to fetch API A?
One solution that most candidates will mention is the use of caching.
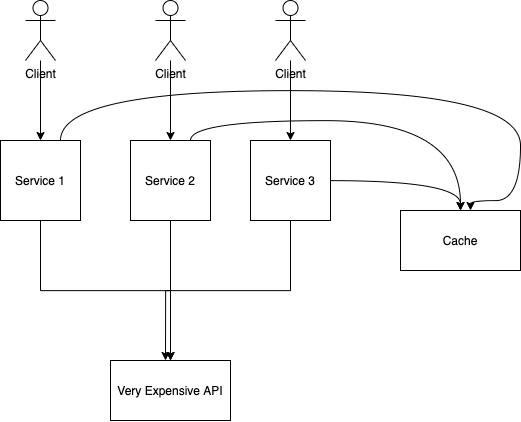
Let’s imagine you want to create a cache. The cache interface looks like this:
The cache has a get and a compareAndSet operations. For get, if the key doesn’t exist, it will return a null value. compareAndSet will compare put the prevValue, the previous value, of the value in the cache. If the prevValue is the one we mentioned, the currValue will override that prevValue. Suppose the prevValue inserted into the parameter is not the last value in the cache. In that case, the currValue will not be inserted into the cache. compareAndSet returns a boolean if the operation has succeeded insert the currValue.
You have to implement getAPI that will incorporate the cache interface:
What they Test You
This question doesn’t just ask you about the trivia things such as the cache invalidation strategy, the cache eviction policy, or the purpose of a cache.
Most candidates have heard of a cache, and the purpose of creating one is to increase your application’s latency. Moreover, a simple Google search can answer those questions.
This question about implementing cache is to test and gauge the candidates’ knowledge of whether or not they have experience writing services and APIs. You can assess whether or not they know about error handling. You can also see if they can write code by implementing a solution engineers use in a real-world scenario.
Most of the rudimentary answers for implementing the getAPI is using an if statement.
Intuition
Call get with the given key. If the operation encounters a cache-miss, call fetchAPIA. Once finish calling fetchAPIA, evoke the compareAndSet operation to refresh the cache with the given key.
The above initial implementation looks good. However, this is fine if you only have one request and only one user. If there are multiple concurrent calls to the cache and they all hit cache miss, the third-party service may get bombarded with multiple concurrent calls. With a high traffic spike on the service all at once, the service may encounter an outage. This phenomenon is often called the cache stampede.
How do you code your function so that it prevents cache stampede?
Candidates who encounter this issue will know how to solve it. However, if they haven’t seen this issue, you can also test their ability to problem solve by seeing how they will solve such an issue.
Furthermore, you can test candidates’ ability to handle the error. What happen if compareAndSet returns a false? Do you do a retry, or do you return the value with an error message?
These questions can sometimes touch different ways from a simple coding exercise. Experienced candidates will know some types of errors you want to recover and some types of errors you want to throw them gracefully.
Solution
The underlying problem with cache stampede is a classic problem in concurrent programming. If multiple threads are trying to access a memory location, how do you ensure that only one value gets access to that memory location? In other words, how do you ensure that only one thread at a time accessing the application? The solution is to use locking.
When it’s time for one of the workers to do some computation on the cache, it will acquire the resources - stopping other workers from computing that memory location. Any other worker with a stale or missing cache will need to wait until the lock is released. Then, they will retry the cache read. The primary data source, therefore, is not overload with the request.
Therefore, any method to avoid cache stampede limits the number of requests to the primary resources. There are multiple ways to solve this problem. Two simple ways are the most versatile method to avoid cache stampede.
Debouncing the request
The first one comes from the common JavaScript practice of preventing duplicate events from firing and causing noise in the system. This is something that frontend-engineer use frequently called Debouncing. What debounce function does is that it delays the invoking function after 100 milliseconds have elapsed since the last time system evoked the debounced function. Doordash did it in their backend using Kotlin Coroutine. However, if you don’t use a specific language with this mechanism, you must implement your debouncing method. Therefore, it is not maybe quite tough to do. Moreover, this solution will require another service or rely on the caller to have that mechanism, which increases dependency within the service.
Compare and Set
The compareAndSet is key in this question because it is the only way that has some synchronization inside.
Insert some keywords in the cache to indicate that there is already one worker doing the fetching. Therefore, another worker can either wait and retry again. For instance, once a worker call cache, and it gets a cache-miss, it will write a value with the key to the cache, such as “in-progress,” to imply to other work that the current key is a cache miss and that there is already a worker fetching the primary source. The catch here is that the calling operation needs to compare and set the process with atomic primitive. Another worker can wait and recursively call the function again to check if the “in-progress” has to turn into something else.
Are we done yet? Did you notice any other possible failures that we need to handle?
There is a scenario regarding the initial compareAndSet returns a false. There is also another scenario where the last compareAndSet returns a false.
The above method didn’t implement what happens when the get(key) returns an in-progress. Should they wait and retry, or should they return a specialized message to the caller saying they are “waiting”?
Closing
This new breed of questions tests candidates’ ability to problem solve and their experience in software development. Experience candidates may know when is good to retry and when is not good to retry. A problem with a mixed implementation of real-world system design is a better question for the tech interview than “how to traverse a BST.”
If that candidate was you, how would you solve the above problem? How should you handle the error above? Are there any other potential scenarios that you need to handle? Do you have any other good interview questions that examine candidates’ problem-solving skills and their experience? Please comment down below and share your thoughts!