Algebraic Data Types have their pros and cons. It enables you to write your application in a type-safe way - when you do pattern matching, it will exhaust all the data types for you. However, there is also a disadvantage of using ADT if your data types keep changing.
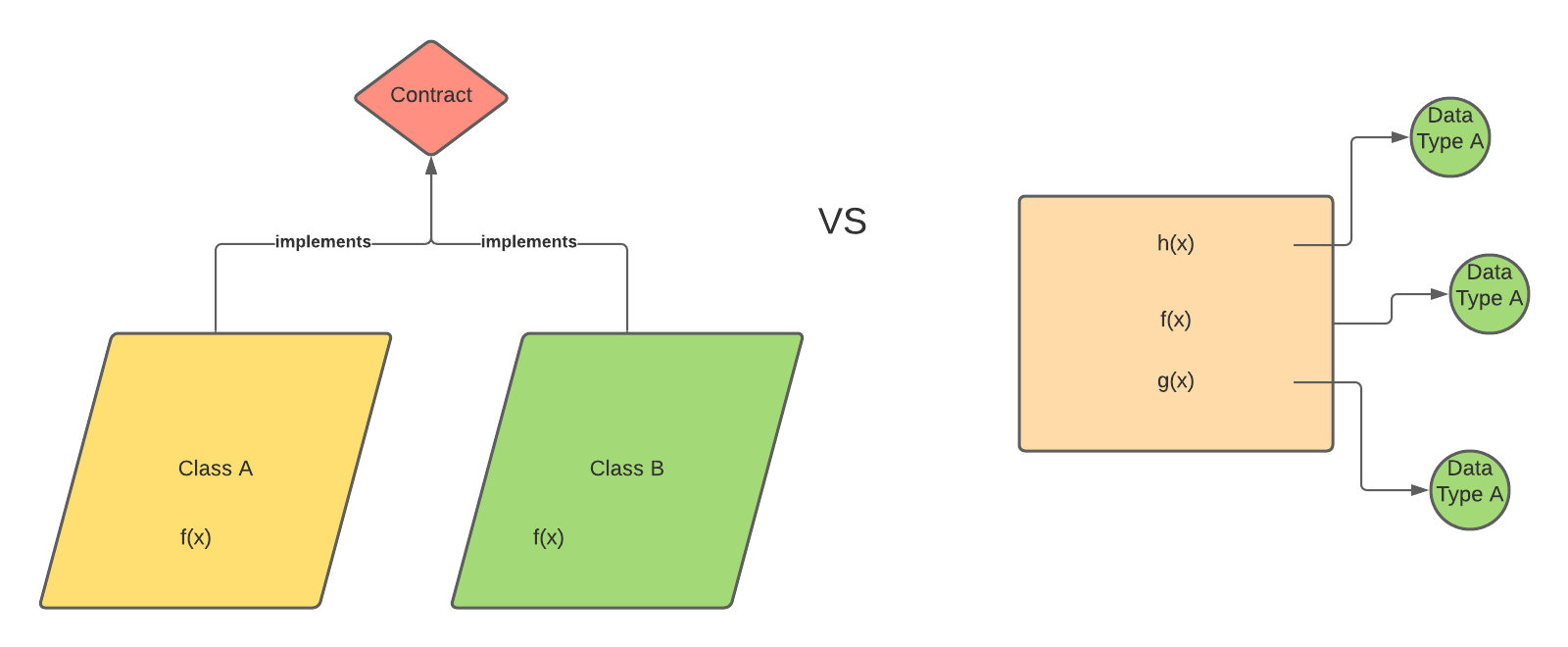
I’ll cut through the chase and give you the answer on the difference - when you write an application with a functional programming paradigm, everything is a group by operation. When we write the program in an object-oriented way, everything is a group based on the objects.
For me, this is a huge discovery! It explains why ADT sometimes can be a pain.
I’ll illustrate what that means - and this can give you a rough idea of what I think the real difference between writing programs in functional programming vs. object-oriented programming.
Let’s make it a Tree data type. On our first try of creating a tree, it will be something like this:
Then, we want to have a function that computes the height of the tree. Let’s make it here:
Then, we want to have a function that computes the sum of all the branches:
From the two functions above, we noticed that once we created our ADT, we will need to implement the cases on each ADT - height and sum needs to implement operation based on two data types - Branch and Leaf.
If we want to implement this in a object oriented way - we will put the method inside the Tree interface:
In an object-oriented way, we are grouping our operation based on per class. Therefore, Branch will have its own function of height and sum, and Leaf will have its own function of height and sum.
These are two ways of structuring your application can have a different impact on how you structure them. Let’s see each of the pros and cons of structuring this way.
Adding a New Data Types
We want to extend Tree to have another data type, `Empty, ‘ representing an empty child in the application.
If we initially implement our Tree Type with ADT and group them in operations, we will need to go through each operation and add an Empty in the pattern matching case.
If we have many functions in our application based on the Tree data types, we have to go through each of them are adding a new Empty case.
However, if we did it in an object-oriented way, we just need to implement a new class, Empty, that extends the Tree trait.
In this scenario, adding new data types will be cumbersome if you group your application based on data types - because we will need to change all operation in the application to include another case. However, in an object-oriented way, since each function is grouped based on the object, adding a new data type needs to implement the Tree interface.
Adding a new operation
We want to add a new operation in the Tree called isEmpty.
If you group your application by separating functions and data types, creating an isEmpty function is relatively straightforward.
On the other hand, if we implement our application in an object-oriented way, we need to go through all the files in our application and implement the isEmpty function because we changed our interface.
This has been a problem in Java. If we have multiple nested inheritances, we need to change all the class that implements the interface.
In this case, the change to add a new operation in a useful way of structuring your application code is local. However, in an object-oriented way of structuring your application, adding a new process will profoundly change the application structure.
What do we learn here?
Structure your data model wisely! We never know the future of the application that we are building on. Therefore, flexibility is critical.
Designing software is partly art and partly technical. Therefore, each developer will have its own style of structuring their application.
There has been a topic all over the web about what is the best practice in structuring your code. However, I think the best way is based on your current application and business logic.
If you know that your data types will keep changing in the future, perhaps creating the value in an object-oriented way will be more flexible. If you know that your data types will most likely stay the same, functionally structuring your data model can benefit the future because new functionality will be added more than new data types.