
AWS Lambda has been widely used to trigger function as a service in a serverless architecture. It is an event-driven computing platform. Lambda runs when an event triggers it. It executes the function that loads into the system.
Amazon offer SDK for writing handler in NodeJS, Python, and Java. You can write NodeJS and Python handler without any external dependencies, and you can write the script right away from the AWS console. However, when it comes to Java, things get a little bit tricky.
You need to write a project, generate a deployment package, and upload it to either an S3 Bucket or import it to the AWS Lambda console. However, since AWS supports Java SDK, the handler method is not hard to construct.
When it comes to writing an AWS Lambda in Scala - not only that I have to deal with all the complexity that arises with writing Lambda in Java, but also find a way to transfer Scala code to Java, by not writing Java code in Scala. That means I have to deal with more dependencies, interoperability, immutability, and built-in features like case class or futures, …etc.
Recently, I did a task to re-try all broken data from the Dead Letter Queue (DLQ) to dev environment for debugging the ETL process. I decided to use Lambda to push the broken data to the Kinesis Stream dev environment and had a hard time writing the Lambda function handler in Scala. After many searching on the internet, I would like to share how I implemented the lambda function handler in the Scala way so that you can use this method in your next project.
There are a lot of built-in libraries on integrating AWS Lambda with Scala. However, with a little tweak in writing it on your own, you don’t have to import more dependencies to your projects that increase its size and complexity.
The Problem
No AWS SDK is written in Scala. Since Scala can run in the JVM environment, we can comprise Scala into a deployment package, JAR, and import the file to AWS.
One of the main problems is interoperability. AWS expects a specific interface to write input and output of its handler. It is easier to construct a handler with a first input handler, or using built-in classes that Amazon created for events, such as S3, SNS..etc) However, if you want your Lambda to take in a JSON input and responds with a JSON output, it gets a bit hairy.
Let’s define a Hello World lambda in Java:
package example;
import com.amazonaws.services.lambda.runtime.Context;
public class Hello {
public String myHandler(String name, Context context) {
return String.format("Hello %s.", name);
}
}This code can translate to Scala like this:
package example;
import com.amazonaws.services.lambda.runtime.Context;
object Hello extends App {
def myHandler(name: String, context: Context): String = s"Hello $name"
}Both of these functions work well because String converts to Java String objects in the Jar file, and AWS can understand it.
In a real-world scenario, we might need to have an input of JSON string and response with a regular value, or another JSON.
This is how it looks like in Java (from AWS documentation):
package example;
import com.amazonaws.services.lambda.runtime.Context;
public class HelloPojo {
// Define two classes/POJOs for use with Lambda function.
public static class RequestClass {
...
}
public static class ResponseClass {
...
}
public static ResponseClass myHandler(RequestClass request, Context context) {
String greetingString = String.format("Hello %s, %s.", request.getFirstName(), request.getLastName());
return new ResponseClass(greetingString);
}
}RequestClass and ResponseClass are Java POJOs with beans. It works because AWS uses Java beans to handle serialization and deserialization of JSON.
How would we implement this in Scala?
package example
import com.amazonaws.services.lambda.runtime.Context;
class Handler extends RequestHandler[Request,Response] {
def handleRequest(input:Request, context:Context): Response = {
Response(s"Hello ${request.firstName} ${request.lastName}.")
}
}A handle request takes in an input and the context and returns an output R into JSON. The most natural way of creating this in Scala is using a case class. Like this:
case class Request(firstName: String, lastName:String)
case class Response(response: String)However, this code doesn’t work when you want to trigger the Lambda.
Why using Case Class doesn’t work like Java Beans
The JSON deserialization uses Java Beans, which requires a default constructor with a getter and a setter. However, Case Class doesn’t have a default constructor – the only way to mimic Java Beans is to create a mutable class that forces its variable to be passed around to multiple functions.
Therefore, you need to translate the above Scala Code to this:
package example
import scala.beans.BeanProperty
class Request(@BeanProperty var firstName: String, @BeanProperty var lastName:String) {
def this() = this("", "", "")
}If you are a Scala Developer, you look at this code with a squinted eye of code smell. One of the advantages of the Scala programming language is immutability. And this is not how you like to code in Scala, right?
Writing Handler with InputStream and OutputStream
Luckily, AWS gives us another option of implementing the handler function with InputStream and OutputStream. In this case, we need to handle the serialization and deserialization ourselves.
Let’s look at how it is implemented in Java:
package example;
import java.io.InputStream;
import java.io.OutputStream;
import com.amazonaws.services.lambda.runtime.RequestStreamHandler;
import com.amazonaws.services.lambda.runtime.Context;
public class Hello implements RequestStreamHandler {
public static void handler(InputStream inputStream, OutputStream outputStream, Context context) throws IOException {
int letter;
while((letter = inputStream.read()) != -1) {
outputStream.write(Character.toUpperCase(letter));
}
}
}Use Source.formInputStream to convert the input into a String type, and deserialize the String into an instance of (name of the type). Then, we can serialize the type (Type name) into a JSON string and write it to AWS in the outputStream.
class MainHandler extends RequestStreamHandler {
override def handleRequest(input: InputStream, output: OutputStream, context: Context): Unit = {
val inputString: String = Source.fromInputStream(input).mkString
decode[RequestFormatter](inputString).map(requestFormatter => {
println(s"${requestFormatter} is here")
// do something .....
output.write(requestFormatter.asJson.noSpaces.toCharArray.map(_.toByte))
})
}
}Putting it Together:
Once you wrote the handler, now it is time to bundle the project into a deployment package and upload it to the AWS Lambda console. Here are the quick steps to make your Lambda runs.
Type assembly , which create a JAR file in the target folder:
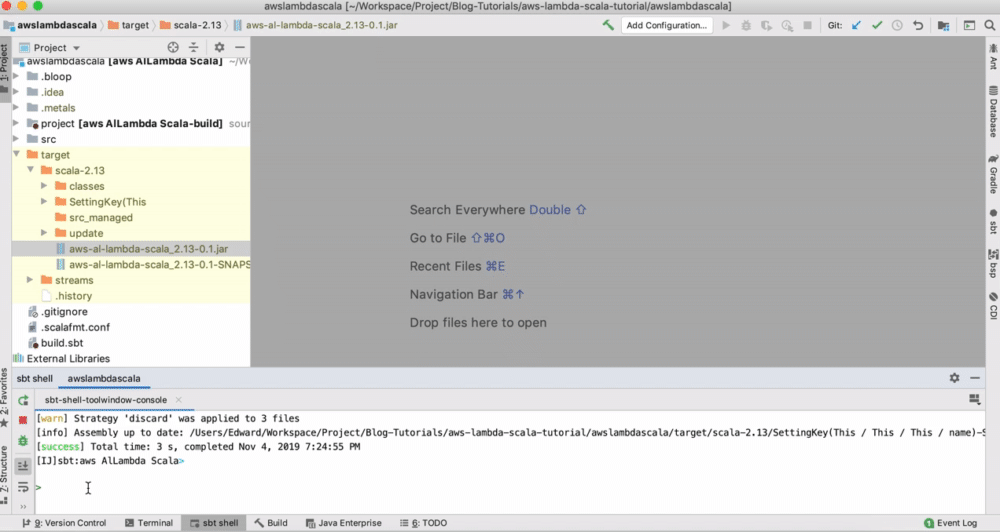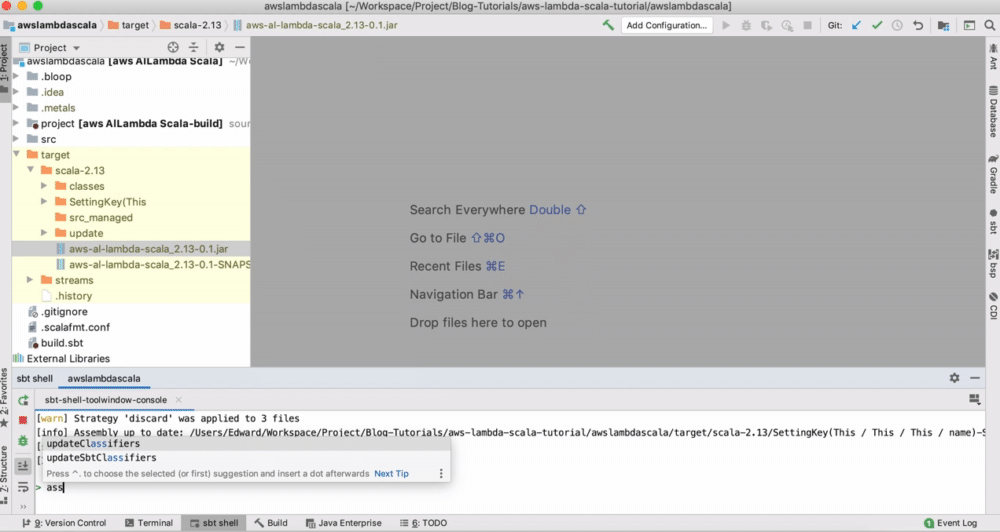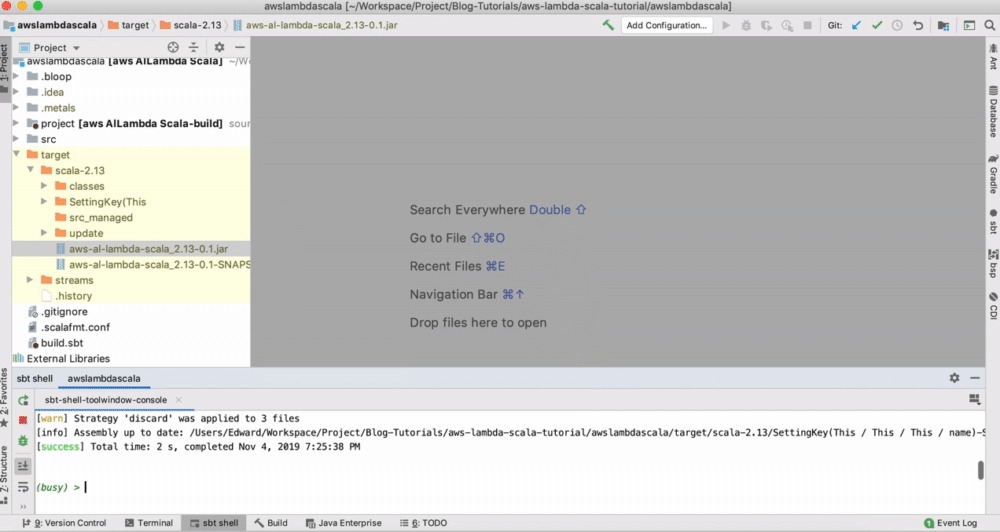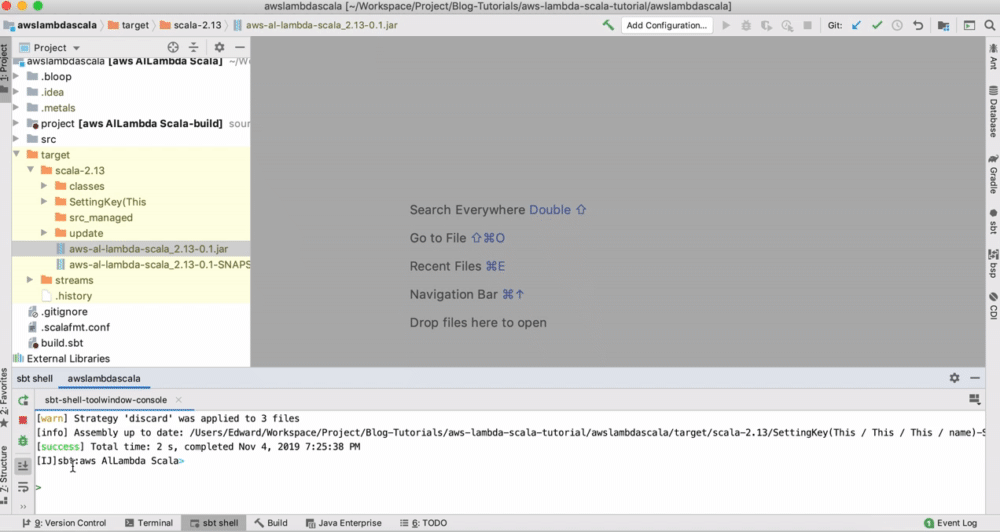
You can also follow the description in the AWS deploying Lambda function.
Go the Lambda Console

Create Your Function (don’t forget the IAM role before create the function so that you have permission)
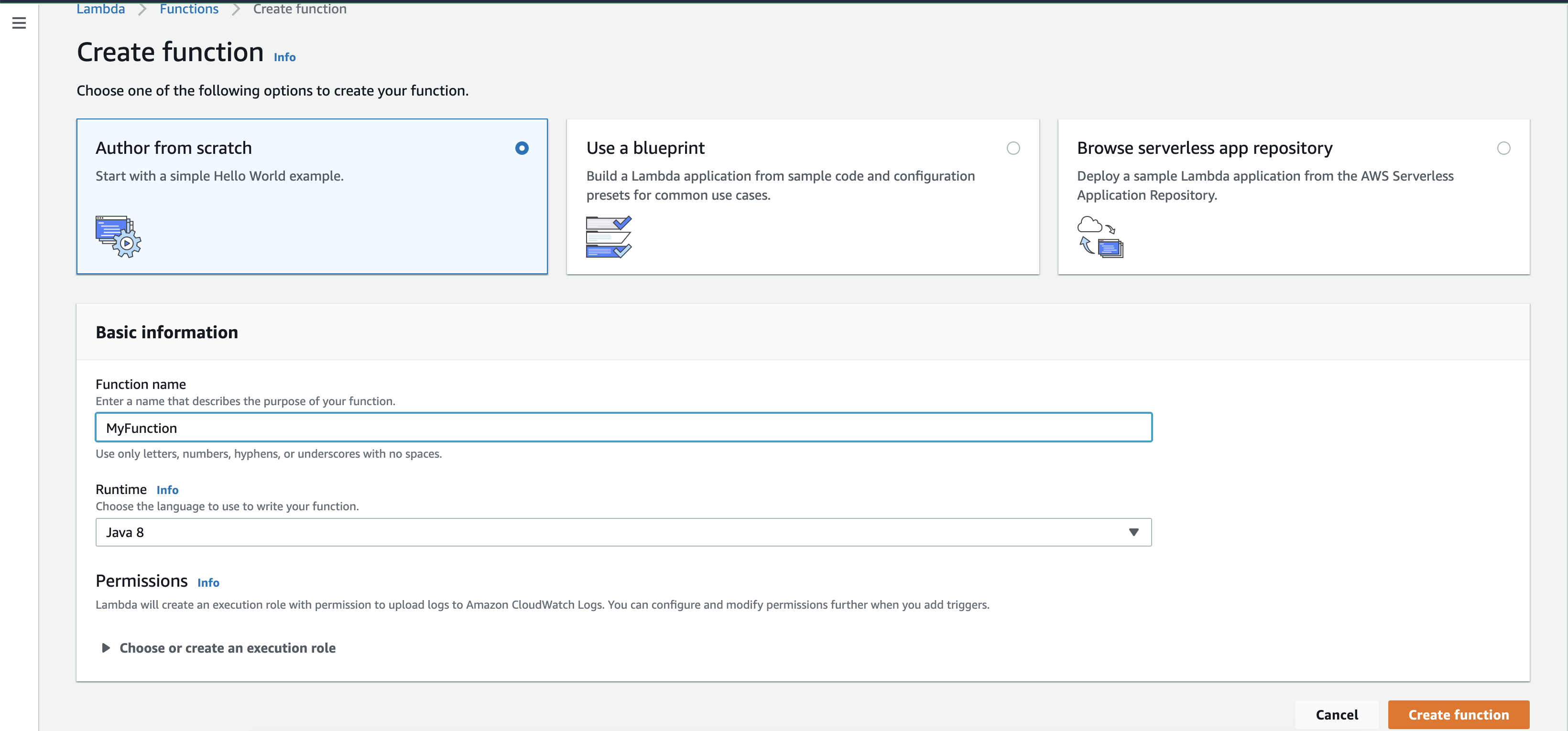
Import the package in the console
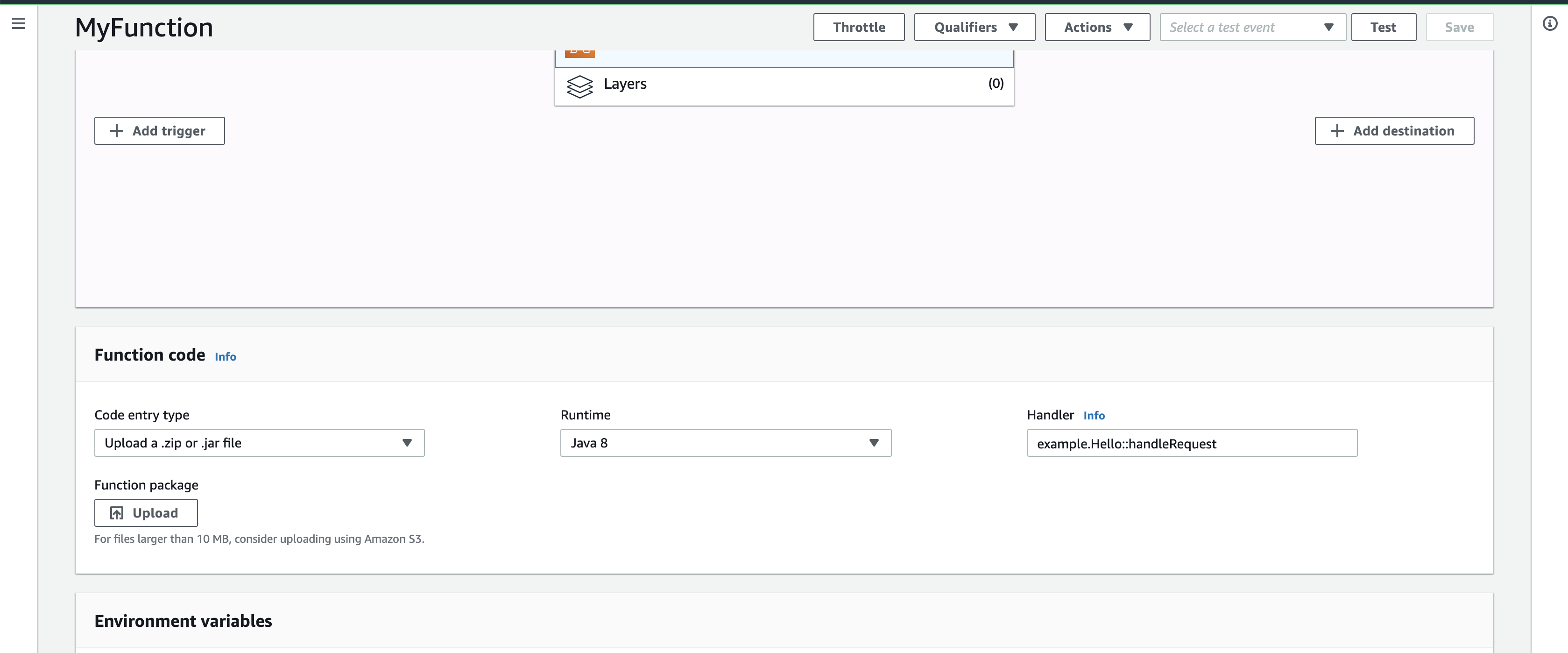
Write the argument
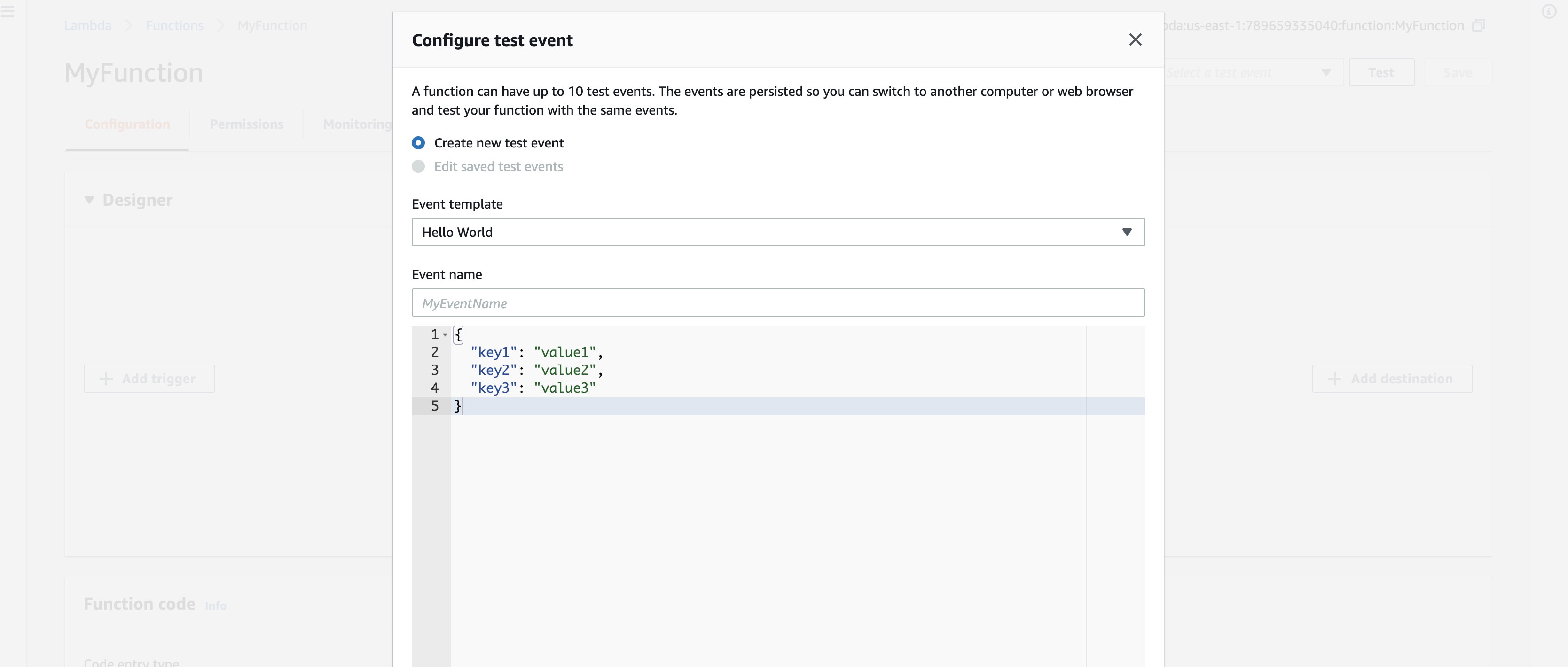
Trigger the function (click on the Test in the console below)
That’s it! I hope you find this simple tutorial on writing AWS Lambda in Scala helpful. Please comment in the section below if you have any questions. If there are any other better ways to implement Lambda in Scala, please share your method in the comment section below!
This is the full code of the tutorial on Github.