
When we talked about Data Processing or doing Big Data ETL, the first that comes to mind is using Hadoop (or Spark). Today, I would like to show another way of creating Data Processing using the Actor System. I will be using classic Akka Actors.
Note: This article will not talk about an Actor System, and introduce an Actor System in Akka. However, I will write another essay explaining the Akka Actor’s introduction, or you can also read the documentation in the Akka side.
Why use Actor System?
Modern distributed systems with demanding requirements encounter challenges that traditional object-oriented programming (OOP) models cannot solve.
One of the fallback examples of OOP in creating distributed systems includes the challenge of encapsulation. If you write a regular thread model in Java, encapsulation doesn’t encapsulate multiple threads in your application. Encapsulation is only valid in the single-threaded model. To be thread-safe for encapsulation to occur, you need to do synchronized. Other fallbacks can be seen in the Akka side.
Goal
I will create an application that will get data from a log CSV file and use a master-worker pattern to process each message.
The goal is to aggregate and count all the occurrence Http Status code in the Log file corresponding to the Log file content and write it to the out.txt file.
Actor Hierarchy
Since there are multiple components involved in getting the data from the source file, splitting the work, and aggregating them, let’s examine the different actors’ role in this application.
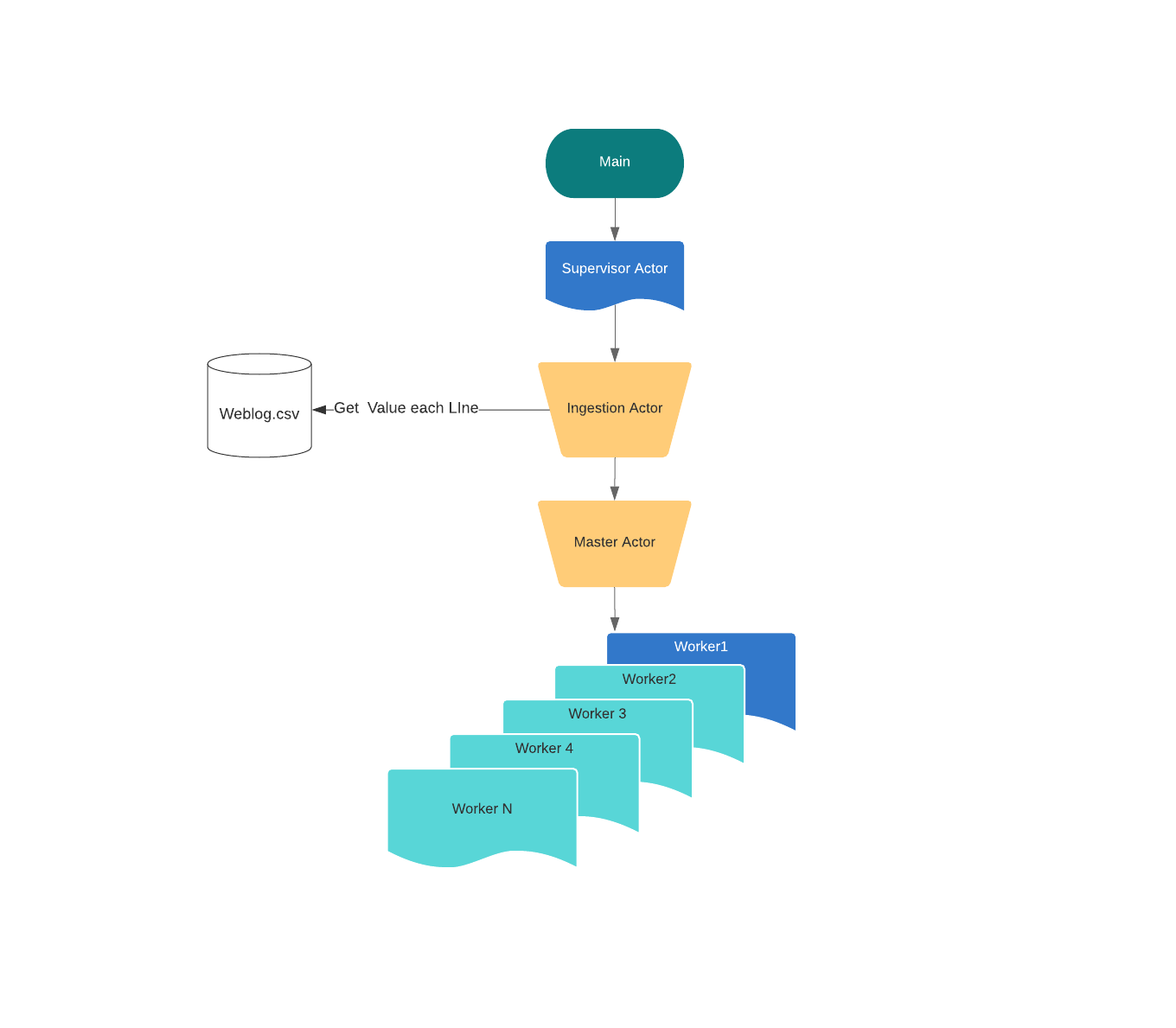
There are four kinds of actors: Supervision Actor, Ingestion Actor, Master Actor, Worker Actor.
Supervision Actor supervises, spawning, and stopping Ingestion Actor. Supervision Actor will handle any sort of event failure in the Ingestion Actor.
Ingestion Actor reads the log file from the source, initialized the Master Actor. It splits the log file to each line and sends each line to the Master Actor. Finally, it will receive the aggregated value from the Master Actor and write that value to the out.txt file.
Master Actor plays a role in creating Worker Actor and delegating tasks to the Worker Actors. It also aggregates the results and sends them back to the Ingestion Actor.
The worker Actor will create all the heavy lifting in process.
The data that we will read is a log file, and it will contain IP, Time, URL, Status:
10.128.2.1,[29/Nov/2017:06:58:55,GET /login.php HTTP/1.1,200
However, the data is not always in the right order, and we need to do a filter to process the data.
In this article, I will walk through the process of the code for Supervisor Actor and Ingestion Actor. Master Actor and Worker Actor will be in part 2.
Let’s go forth and conquer.
Main
Before walking you through all the code in the application, here is the Main function for calling the Data processing application:
object Main extends App {
val system = ActorSystem("DataProcessingAkka")
val supervisorActor = system.actorOf(Supervisor.props(100), "supervisor")
supervisorActor ! Supervisor.Start
}
It creates an actor system, and create a supervision actor with the arguments of 100 workers to process the data. Then, it sends Supervisor.start message to the Supervisor Actor.
Supervisor Actor
Akka provides fault tolerance mechanisms on handling errors within actors, or watching those actors and do some sort of behavior if it encounters any failure.
When an actor fails, it suspends its children, and send a special message to its parent. Then, parents can either start or stop their children.
However, in this article, I won’t use the Supervisor Actor and various kinds of routing strategies that exist in the Akka.
It will be a simple Supervisor actor that will start and stop the application once it is finished.
Let’s look at the code for Supervisor Actor:
class Supervisor(nWorker: Int) extends Actor with ActorLogging {
override def receive: Receive = {
case Start =>
val ingestion = context.actorOf(Props[Ingestion], "ingestion")
ingestion ! Ingestion.StartIngestion(nWorker)
case Stop =>
log.info("[Supervisor] All things are done, stopping the system")
context.system.terminate()
}
}
Supervisor companion object:
object Supervisor {
case object Start
case object Stop
// good way pass create an actor
def props(parallelism: Int) = Props(new Supervisor(parallelism))
}
Using def props(...) in the companion object is a good rule of thumb to create an Actor with the props so that it locks in the arguments when creating the ActorRef.
Once the Supervisor actor received the Start message from Main, it will create Ingestion actor as its children, and send a StartIngestion message with the amount of Worker needs to be processed to the Ingestion Actor.
One thing to note here is - the thought process of creating an Actor is much like thinking of how the actor should react when they received a message.
If the Supervisor Actor receives a Start message, it will do some sort of work. If the Supervisor Actor receives a Stop message, it will shut down the actor system to release the thread that it has allocated.
Ingestion Actor
The Ingestion actor will initialize the Master Actor, gets all the file to the master Actor, and collects the result and write it to out.txt.
Let’s look at the code for Ingestion Actor:
class Ingestion extends Actor with ActorLogging with IngestionHandler {
import Ingestion._
val inputStream = openInputStream
var masterNode: ActorRef = context.actorOf(Master.props(context.self), "masterNode")
override def receive: Receive = {
case StartIngestion(nWorker) =>
log.info("[Ingestion] Initializing Worker ...")
masterNode ! Master.InitializeWorker(nWorker)
case Master.WorkerInitialized =>
log.info("[Ingestion] worker is initialized. Getting lines from source and send to masterNode ...")
Source.fromInputStream(inputStream).getLines().toList.filter(isValidIp).foreach(masterNode ! Data(_))
inputStream.close()
case Aggregate(result) =>
log.info(s"[Ingestion] total status Code: ${result.keys.map(k => s"$k -> ${result(k).length}").toString()}")
val lines = result.keys.map { key =>
s"Status : ${key} has a total of ${result(key).length} amount}"
}
writeToOutputFile(lines)
context.parent ! Supervisor.Stop
}
}
Ingestion Companion Object:
object Ingestion {
case class StartIngestion(nWorker: Int)
case class Data(logString: String)
}
Once the Supervisor Actor creates Ingestion actor, it will automatically fetch the source value as an input stream and create a Master actor.
When the Ingestion actor receives the StartIngestion message, it sends a message to Master actor, telling the Master actor to initialized all its children.
Once the Master actor is initialized, Ingestion will assume that Master actor will send a confirmation message to let the Ingestion start sending each text line to Master to processed. The Ingestion actor will get each line from the file, filter the ones that don’t have a valid IP and send the valid ones to the Master actor.
Finally, the Aggregate(result) is when the Master actor sends the result back to Ingestion actor. Ingestion actor will do a little processing on the outcome and write the result to the output file. Once it finished writing the result to the output file, it will send a message to the Supervision actor to close the application.
When dealing with a lot of data processing inside Actors, one best practice is to separate the logic to a handler trait. Once you separate the logic from the handler trait, you can quickly test the specific functionality of the handler trait.
Let’s look at the Ingestion Handler trait, which contains all the data processing functionality for Ingestion actor:
trait IngestionHandler {
def isValidIp(line: String): Boolean = {
val ipRegex: Regex = """.*?(\d{1,3})\.(\d{1,3})\.(\d{1,3})\.(\d{1,3}).*""".r
ipRegex.pattern.matcher(line.split(",")(0)).matches()
}
def openInputStream: InputStream = getClass.getResourceAsStream("/weblog.csv")
def writeToOutputFile(lines: Iterable[String]) = {
val path = getClass.getResource("/out.txt").getPath
File(path).createIfNotExists().clear().appendLines(lines.mkString(","))
}
}
The handler trait includes functionality for reading a file, writing to a file, and checking for a valid address.
Flow for Master-Worker actors
Before we get into the Master and Worker actors, there are two different approaches to design the flow of the system:
The first approach - the actor sends the execution message to its workers. Then, the master actor will send confirmation messages again to its workers. Aggregate all the result and send back to Ingestion actor.
If we implement this flow, we will need to have a state in each Worker, resultMap, to store all the Log that is processed. Then, the Master actor will also need to have a resultMap that contains all the resultMap from its Worker.
The second approach is to hold the state in the Master actor since Master will need to aggregate all the resultMap anyways. Therefore, the Worker actor will send the result back to the Master actor once it finishes the current process task, and get the next job from the mailbox.
You don’t need to keep any state in the Worker actor and Master doesn’t need to send a notification message again to the Worker - asking for the result.
We will implement approach number 2 in this article.
Master Actor
Master Actor is the hardest part of this application because it is an orchestration role.
To recap, the Master actor will initialize all the Worker actors, delegating tasks to its Worker actors and aggregating the result from each Worker Actors.
We will be using a simple round-robin technique for task assignments for illustration purposes. However, if you want to get fancy and efficient, you can use the Akka Routing that supports all kinds of routing logic.
Let’s take a look at the code of for the Master actor:
class Master(parent: ActorRef) extends Actor with ActorLogging {
override def receive: Receive = preInitialize
def preInitialize: Receive = {
case InitializeWorker(nWorker) =>
log.info(s"[Master] Initializing $nWorker worker(s)...")
val workers = (0 to nWorker).toVector.map(id => context.actorOf(Props[Worker], s"${id}-worker"))
sender() ! WorkerInitialized
context.become(
workerInitialized(
currentWorkerId = 0,
currentTaskId = 0,
workers = workers,
Set.empty[Int],
resultMap = Map.empty[String, List[Log]]
)
)
}
def workerInitialized(
currentWorkerId: Int,
currentTaskId: Int,
workers: Vector[ActorRef],
taskIdSet: Set[Int],
resultMap: Map[String, List[Log]]
): Receive = {
case Data(logString) =>
log.info(s"[Master] received $logString assigning taskId $currentTaskId to worker $currentWorkerId")
val currentWorker = workers(currentWorkerId)
val newTaskIdSet = taskIdSet + currentTaskId
currentWorker ! Execute(currentTaskId, logString, context.self)
val newTaskId = currentTaskId + 1
val newWorkerId = (currentWorkerId + 1) % workers.length
context.become(workerInitialized(newWorkerId, newTaskId, workers, newTaskIdSet, resultMap))
case Worker.Result(id, result) =>
log.info(s"[Master] Received result $result from taskId $id")
val newTaskIdSet = taskIdSet - id
val newResultMap = result match {
case log @ Log(_, _, _, status) =>
val logList = resultMap.getOrElse(status, List.empty[Log])
resultMap + (status -> (log :: logList))
}
if (newTaskIdSet.isEmpty) {
log.info(s"[Master] All task is done, sending result back to ${parent.path}")
parent ! Aggregate(newResultMap)
} else {
log.info(s"[Master] Task is not yet all done, waiting for other workers to send back results")
context.become(workerInitialized(currentWorkerId, currentTaskId, workers, newTaskIdSet, newResultMap))
}
}
}
Master companion object:
object Master {
case class InitializeWorker(nWorker: Int)
case object WorkerInitialized // send back to the ingestion
case class Aggregate(numberOfStatus: Map[String, List[Log]]) // get all the aggregated result from worker (status code -> number)
def props(parent: ActorRef): Props = Props(new Master(parent))
}
First, the Master actor received an InitializeWorker(nWorker) with the amount of Worker to initialized.
Once the Worker is initialized, the Master actor will send the WorkerInitialized message back to Ingestion actor and switch its state to workerInitialized.
In the workerInitialized state, the Master actor received log string, Data(logString) from Ingestion actor, and delegate the task to its Worker in a round-robin logic.
I assigned each task with a taskId and kept track of that taskId in the set. Each time the Master sends the job to the Worker, it will add the new taskId to the taskId set. Each time when the Worker finished running the taskId and send the result back to the Master actor, the Master actor will remove the taskId from the taskId set.
When the Worker actor finished processing the data and send back the result to Master actor, the master actor will add the new result to a Map and remove the taskId from the taskId set.
When will Master actor know to send the result back to Ingestion actor?
When all the taskId set is empty, all workers finished processing all task. The master actor sends the result back to Ingestion.
Note over here that I used context.become and assign workerInitialized and preInitialized receive handler. It is a method not only to avoid any mutated state within actors but also to predefined each of the states inside the actor.
Each predefined state inside the actor can be refactored and turn into a Finite State Machine FSM if you would like.
Having a different state also helps for understanding what action does the actor takes on each state of the application process.
Worker Actor
The Worker actor will convert the line of String a Log case class and send the Log case class back to the Master actor.
Let’s look at the Worker actor:
class Worker extends Actor with WorkerHandler {
override def receive: Receive = {
case Execute(id, task, sender) =>
sender ! Result(id, convertToLog(task))
}
}
Let’s look at the Worker Companion object:
object Worker {
case class Log(ip: String, time: Date, url: String, status: String)
case class Date(year: Int, month: String, date: Int, time: String)
case class Execute(taskId: Int, task: String, replyTo: ActorRef) // received Execute Task
case class Result(workerId: Int, result: Log) // Send Result
}
Let’s look at the Worker handler:
trait WorkerHandler {
def convertToLog(line: String): Log = line.split(",").toList match {
case ip :: time :: url :: status :: _ =>
Log(ip, convertToDate(time), url, status)
}
def convertToDate(time: String): Date = time.substring(1).split("/").toList match {
case date :: month :: yearAndTime :: _ =>
yearAndTime.split(":").toList match {
case year :: rest => Date(year.toInt, month, date.toInt, rest.mkString(":"))
}
}
}
Once the Worker received Execute(line) messages, it will convert the string to a Log case class. Then, it will send the result back to the Master actor.
Summary
In this series, I introduced a simple data processing application with the Actor System. I also explained why to use an Actor System in creating a distributed system.
Lastly, I explained my thought process of designing the actor hierarchy and dived deep into the thought process of thinking reactively when creating Actors in your application.
I hope you gained some understanding of how to implement and design an Actor System.
All sources are on here.
This post was inspired Aleksandar. It is a post that I saw while I was learning Akka actors.